Recently, a lot of new non-relational databases have cropped up both inside and outside the cloud. One key message this sends is, “if you want vast, on-demand scalability, you need a non-relational database”.
If that is true, then is this a sign that the once mighty relational database finally has a chink in its armor? Is this a sign that relational databases have had their day and will decline over time? In this post, we’ll look at the current trend of moving away from relational databases in certain situations and what this means for the future of the relational database.
Relational databases have been around for over 30 years. During this time, several so-called revolutions flared up briefly, all of which were supposed to spell the end of the relational database. All of those revolutions fizzled out, of course, and none even made a dent in the dominance of relational databases.
First, Some Background
A relational database is essentially a group of tables (entities). Tables are made up of columns and rows (tuples). Those tables have constraints, and relationships are defined between them. Relational databases are queried using SQL, and result sets are produced from queries that access data from one or more tables. Multiple tables being accessed in a single query are “joined” together, typically by a criterion defined in the table relationship columns. Normalization is a data-structuring model used with relational databases that ensures data consistency and removes data duplication.
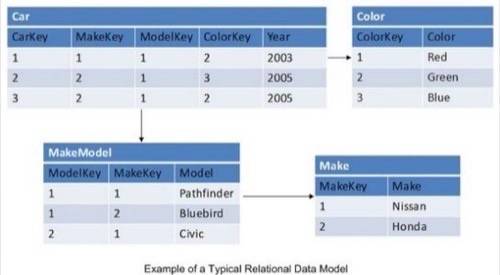
Relational databases are facilitated through Relational Database Management Systems (RDBMS). Almost all database systems we use today are RDBMS, including those of Oracle, SQL Server, MySQL, Sybase, DB2, TeraData, and so on.
The reasons for the dominance of relational databases are not trivial. They have continually offered the best mix of simplicity, robustness, flexibility, performance, scalability, and compatibility in managing generic data.
However, to offer all of this, relational databases have to be incredibly complex internally. For example, a relatively simple SELECT statement could have hundreds of potential query execution paths, which the optimizer would evaluate at run time. All of this is hidden to us as users, but under the cover, RDBMS determines the “execution plan” that best answers our requests by using things like cost-based algorithms.
The Problem with Relational Databases
Even though RDBMS have provided database users with the best mix of simplicity, robustness, flexibility, performance, scalability, and compatibility, their performance in each of these areas is not necessarily better than that of an alternate solution pursuing one of these benefits in isolation. This has not been much of a problem so far because the universal dominance of RDBMS has outweighed the need to push any of these boundaries. Nonetheless, if you really had a need that couldn’t be answered by a generic relational database, alternatives have always been around to fill those niches.
Today, we are in a slightly different situation. For an increasing number of applications, one of these benefits is becoming more and more critical; and while still considered a niche, it is rapidly becoming mainstream, so much so that for an increasing number of database users this requirement is beginning to eclipse others in importance. That benefit is scalability. As more and more applications are launched in environments that have massive workloads, such as web services, their scalability requirements can, first of all, change very quickly and, secondly, grow very large. The first scenario can be difficult to manage if you have a relational database sitting on a single in-house server. For example, if your load triples overnight, how quickly can you upgrade your hardware? The second scenario can be too difficult to manage with a relational database in general.
Relational databases scale well, but usually only when that scaling happens on a single server node. When the capacity of that single node is reached, you need to scale out and distribute that load across multiple server nodes. This is when the complexity of relational databases starts to rub against their potential to scale. Try scaling to hundreds or thousands of nodes, rather than a few, and the complexities become overwhelming, and the characteristics that make RDBMS so appealing drastically reduce their viability as platforms for large distributed systems.
For cloud services to be viable, vendors have had to address this limitation, because a cloud platform without a scalable data store is not much of a platform at all. So, to provide customers with a scalable place to store application data, vendors had only one real option. They had to implement a new type of database system that focuses on scalability, at the expense of the other benefits that come with relational databases.
These efforts, combined with those of existing niche vendors, have led to the rise of a new breed of database management system.
Next page: The New Breed
The New Breed
This new kind of database management system is commonly called a key/value store. In fact, no official name yet exists, so you may see it referred to as document-oriented, Internet-facing, attribute-oriented, distributed database (although this can be relational also), sharded sorted arrays, distributed hash table, and key/value database. While each of these names point to specific traits of this new approach, they are all variations on one theme, which we’ll call key/value databases.
Whatever you call it, this “new” type of database has been around for a long time and has been used for specialized applications for which the generic relational database was ill-suited. But without the scale that web and cloud applications have brought, it would have remained a mostly unused subset. Now, the challenge is to recognize whether it or a relational database would be better suited to a particular application.
Relational databases and key/value databases are fundamentally different and designed to meet different needs. A side-by-side comparison only takes you so far in understanding these differences, but to begin, let’s lay one down:
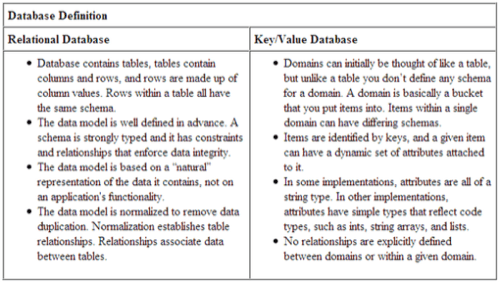
No Entity Joins
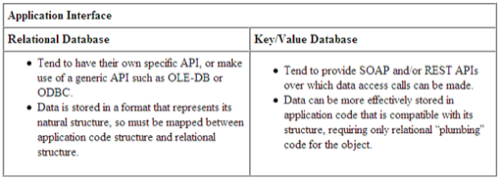
Key/value databases are item-oriented, meaning all relevant data relating to an item are stored within that item. A domain (which you can think of as a table) can contain vastly different items. For example, a domain may contain customer items and order items. This means that data are commonly duplicated between items in a domain. This is accepted practice because disk space is relatively cheap. But this model allows a single item to contain all relevant data, which improves scalability by eliminating the need to join data from multiple tables. With a relational database, such data needs to be joined to be able to regroup relevant attributes.
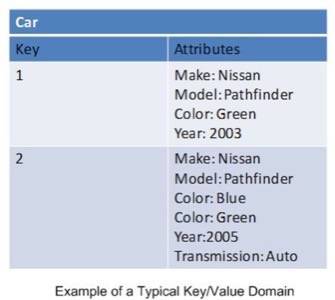
But while the need for relationships is greatly reduced with key/value databases, certain ones are inevitable. These relationships usually exist among core entities. For example, an ordering system would have items that contain data about customers, products, and orders. Whether these reside on the same domain or separate domains is irrelevant; but when a customer places an order, you would likely not want to store both the customer and product’s attributes in the same order item.
Instead, orders would need to contain relevant keys that point to the customer and product. While this is perfectly doable in a key/value database, these relationships are not defined in the data model itself, and so the database management system cannot enforce the integrity of the relationships. This means you can delete customers and the products they have ordered. The responsibility of ensuring data integrity falls entirely to the application.

Key/Value Stores: The Good
There are two clear advantages of key/value databases to relational databases.
Suitability for Clouds
The first benefit is that they are simple and thus scale much better than today’s relational databases. If you are putting together a system in-house and intend to throw dozens or hundreds of servers behind your data store to cope with what you expect will be a massive demand in scale, then consider a key/value store.
Because key/value databases easily and dynamically scale, they are also the database of choice for vendors who provide a multi-user, web services platform data store. The database provides a relatively cheap data store platform with massive potential to scale. Users typically only pay for what they use, but their usage can increase as their needs increase. Meanwhile, the vendor can scale the platform dynamically based on the total user load, with little limitation on the entire platform’s size.
More Natural Fit with Code
Relational data models and Application Code Object Models are typically built differently, which leads to incompatibilities. Developers overcome these incompatibilities with code that maps relational models to their object models, a process commonly referred to as object-to-relational mapping.This process, which essentially amounts to “plumbing” code and has no clear and immediate value, can take up a significant chunk of the time and effort that goes into developing the application. On the other hand, many key/value databases retain data in a structure that maps more directly to object classes used in the underlying application code, which can significantly reduce development time.
Other arguments in favor of this type of data storage, such as “Relational databases can become unwieldy” (whatever that means), are less convincing. But before jumping on the key/value database bandwagon, consider the downsides.
Key/Value Stores: The Bad
The inherent constraints of a relational database ensure that data at the lowest level have integrity. Data that violate integrity constraints cannot physically be entered into the database. These constraints don’t exist in a key/value database, so the responsibility for ensuring data integrity falls entirely to the application. But application code often carries bugs. Bugs in a properly designed relational database usually don’t lead to data integrity issues; bugs in a key/value database, however, quite easily lead to data integrity issues.
One of the other key benefits of a relational database is that it forces you to go through a data modeling process. If done well, this modeling process create in the database a logical structure that reflects the data it is to contain, rather than reflecting the structure of the application. Data, then, become somewhat application-independent, which means other applications can use the same data set and application logic can be changed without disrupting the underlying data model. To facilitate this process with a key/value database, try replacing the relational data modeling exercise with a class modeling exercise, which creates generic classes based on the natural structure of the data.
And don’t forget about compatibility. Unlike relational databases, cloud-oriented databases have little in the way of shared standards. While they all share similar concepts, they each have their own API, specific query interfaces, and peculiarities. So, you will need to really trust your vendor, because you won’t simply be able to switch down the line if you’re not happy with the service. And because almost all current key/value databases are still in beta, that trust is far riskier than with old-school relational databases.
Limitations on Analytics
In the cloud, key/value databases are usually multi-tenanted, which means that a lot of users and applications will use the same system. To prevent any one process from overloading the shared environment, most cloud data stores strictly limit the total impact that any single query can cause. For example, with SimpleDB, you can’t run a query that takes longer than 5 seconds. With Google’s AppEngine Datastore, you can’t retrieve more than 1000 items for any given query.
These limitations aren’t a problem for your bread-and-butter application logic (adding, updating, deleting, and retrieving small numbers of items). But what happens when your application becomes successful? You have attracted many users and gained lots of data, and now you want to create new value for your users or perhaps use the data to generate new revenue. You may find yourself severely limited in running even straightforward analysis-style queries. Things like tracking usage patterns and providing recommendations based on user histories may be difficult at best, and impossible at worst, with this type of database platform.
In this case, you will likely have to implement a separate analytical database, populated from your key/value database, on which such analytics can be executed. Think in advance of where and how you would be able to do that? Would you host it in the cloud or invest in on-site infrastructure? Would latency between you and the cloud-service provider pose a problem? Does your current cloud-based key/value database support this? If you have 100 million items in your key/value database, but can only pull out 1000 items at a time, how long would queries take?
Ultimately, while scale is a consideration, don’t put it ahead of your ability to turn data into an asset of its own. All the scaling in the world is useless if your users have moved on to your competitor because it has cooler, more personalized features.
Next page: Cloud-Service Contenders
Cloud-Service Contenders
A number of web service vendors now offer multi-tenanted key/value databases on a pay-as-you-go basis. Most of them meet the criteria discussed to this point, but each has unique features and varies from the general standards described thus far. Let’s take a look now at particular databases, namely SimpleDB, Google AppEngine Datastore, and SQL Data Services.
Amazon: SimpleDB
SimpleDB is an attribute-oriented key/value database available on the Amazon Web Services platform. SimpleDB is still in public beta; in the meantime, users can sign up online for a “free” version — free, that is, until you exceed your usage limits.

SimpleDB has several limitations. First, a query can only execute for a maximum of 5 seconds. Secondly, there are no data types apart from strings. Everything is stored, retrieved, and compared as a string, so date comparisons won’t work unless you convert all dates to ISO8601 format. Thirdly, the maximum size of any string is limited to 1024 bytes, which limits how much text (i.e. product descriptions, etc.) you can store in a single attribute. But because the schema is dynamic and flexible, you can get around the limit by adding “ProductDescription1,” “ProductDescription2,” etc. The catch is that an item is limited to 256 attributes. While SimpleDB is in beta, domains can’t be larger than 10 GB, and entire databases cannot exceed 1 TB.
One key feature of SimpleDB is that it uses an eventual consistency model.This consistency model is good for concurrency, but means that after you have changed an attribute for an item, those changes may not be reflected in read operations that immediately follow. While the chances of this actually happening are low, you should account for such situations. For example, you don’t want to sell the last concert ticket in your event booking system to five people because your data wasn’t consistent at the time of sale.
Google AppEngine Data Store
Google’s AppEngine Datastore is built on BigTable, Google’s internal storage system for handling structured data. In and of itself, the AppEngine Datastore is not a direct access mechanism to BigTable, but can be thought of as a simplified interface on top of BigTable.

The AppEngine Datastore supports much richer data types within items than SimpleDB, including list types, which contain collections within a single item.
You will almost certainly use this data store if you plan on building applications within the Google AppEngine. However, unlike with SimpleDB, you cannot currently interface with the AppEngine Datastore (or with BigTable) using an application outside of Google’s web service platform.
Microsoft: SQL Data Services
SQL Data Services is part of the Microsoft Azure Web Services platform. The SDS service is also in beta and so is free but has limits on the size of databases. SQL Data Services is actually an application itself that sits on top of many SQL servers, which make up the underlying data storage for the SDS platform. While the underlying data stores may be relational, you don’t have access to these; SDS is a key/value store, like the other platforms discussed thus far.

Microsoft seems to be alone among these three vendors in acknowledging that while key/value stores are great for scalability, they come at the great expense of data management, when compared to RDBMS. Microsoft’s approach seems to be to strip to the bare bones to get the scaling and distribution mechanisms right, and then over time build up, adding features that help bridge the gap between the key/value store and relational database platform.
Non-Cloud Service Contenders
Outside the cloud, a number of key/value database software products exist that can be installed in-house. Almost all of these products are still young, either in alpha or beta, but most are also open source; having access to the code, you can perhaps be more aware of potential issues and limitations than you would with close-source vendors.
CouchDB
CouchDB is a free, open-source, document-oriented database. Derived from the key/value store, it uses JSON to define an item’s schema. CouchDB is meant to bridge the gap between document-oriented and relational databases by allowing “views” to be dynamically created using JavaScript. These views map the document data onto a table-like structure that can be indexed and queried.

At the moment, CouchDB isn’t really a distributed database. It has replication functions that allow data to be synchronized across servers, but this isn’t the kind of distribution needed to build highly scalable environments. The CouchDB community, though, is no doubt working on this.
Project Voldemort
Project Voldemort is a distributed key/value database that is intended to scale horizontally across a large numbers of servers. It spawned from work done at LinkedIn and is reportedly used there for a few systems that have very high scalability requirements. Project Voldemort also uses an eventual consistency model, based on Amazon’s.
Project Voldemort is very new; its website went up in only the last few weeks.
Mongo
Mongo is the database system being developed at 10gen by Geir Magnusson and Dwight Merriman (whom you may remember from DoubleClick). Like CouchDB, Mongo is a document-oriented JSON database, except that it is designed to be a true object database, rather than a pure key/value store. Originally, 10gen focused on putting together a complete web services stack; more recently, though, it has refocused mainly on the Mongo database. The beta release is scheduled for mid-February.

Drizzle
Drizzle can be thought of as a counter-approach to the problems that key/value stores are meant to solve. Drizzle began life as a spin-off of the MySQL (6.0) relational database. Over the last few months, its developers have removed a host of non-core features (including views, triggers, prepared statements, stored procedures, query cache, ACL, and a number of data types), with the aim of creating a leaner, simpler, faster database system. Drizzle can still store relational data; as Brian Aker of MySQL/Sun puts it, “There is no reason to throw out the baby with the bath water.” The aim is to build a semi-relational database platform tailored to web- and cloud-based apps running on systems with 16 cores or more.

Making a Decision
Ultimately, there are four reasons why you would choose a non-relational key/value database platform for your application:
- Your data is heavily document-oriented, making it a more natural fit with the key/value data model than the relational data model.
- Your development environment is heavily object-oriented, and a key/value database could minimize the need for “plumbing” code.
- The data store is cheap and integrates easily with your vendor’s web services platform.
- Your foremost concern is on-demand, high-end scalability — that is, large-scale, distributed scalability, the kind that can’t be achieved simply by scaling up.
But in making your decision, remember the database’s limitations and the risks you face by branching off the relational path.
For all other requirements, you are probably best off with the good old RDBMS. So, is the relational database doomed? Clearly not. Well, not yet at least.
Top image by Tim Morgan

















