It’s hard to keep track of all the database-related terms you hear these days. What constitutes “big data”? What is NoSQL, and why are your developers so interested in it? And now “NewSQL”? Where do in-memory databases fit into all of this? In this series, we’ll untangle the mess of terms and tell you what you need to know.

In Part One we covered data, big data, databases, relational databases and other foundational issues. In this section we’ll talk about data warehouses, ACID compliance, distributed databases and more. In part three, we’ll cover non-relational databases, NoSQL and related concepts.
Data Warehouse
A data warehouse is a centralized database that is shared by an organization. According to Information Management, a data warehouse is “typically a subject database that allows users to tap into a company’s vast store of operational data to track and respond to business trends and facilitate forecasting and planning efforts.”
Analytics
Wikipedia defines analytics as “the application of computer technology, operational research, and statistics to solve problems in business and industry.” However there has been controversy over the definition of the expression. Some simply use it interchangeably with “statistics” or “data analysis.” Others believe analytics needs to have an automated component.
Many encounter the term for the first time to refer to Web analytics, which is the practice of collecting and analyzing data on the use of websites – including, but not limited to, traffic analysis.
Business Intelligence
Business intelligence refers to the use of software to analyze business data, usually data stored in a data warehouse. According to Information Management:
“Business intelligence serves two main purposes. It monitors the financial and operational health of the organization (reports, alerts, alarms, analysis tools, key performance indicators and dashboards). It also regulates the operation of the organization, providing two- way integration with operational systems and information feedback analysis.”
Some consider business intelligence to be a subcategory of “business analytics,” though IBM has been using the term “business analytics” to refer to automated business intelligence.
Data Mining
From the Wikipedia entry on data mining:
“Data mining (the analysis step of the Knowledge Discovery in Databases process, or KDD), a relatively young and interdisciplinary field of computer science, is the process of discovering new patterns from large data sets involving methods from statistics and artificial intelligence but also database management. In contrast to for example machine learning, the emphasis lies on the discovery of previously unknown patterns as opposed to generalizing known patterns to new data.
“The term is a buzzword, and is frequently misused to mean any form of large scale data or information processing (collection, extraction, warehousing, analysis and statistics) but also generalized to any kind of computer decision support system including artificial intelligence, machine learning and business intelligence. In the proper use of the word, the key term is discovery, commonly defined as “detecting something new”. Often the more general terms “(large scale) data analysis” or “analytics” are more appropriate.”
Columnar Database / Column-Oriented Database
Columnar databases differ from most traditional RDBMSes in that they store data primarily by column instead of row. To use our blog post example from the Relational Database section of Part One, the same example in a columnar database would look like:
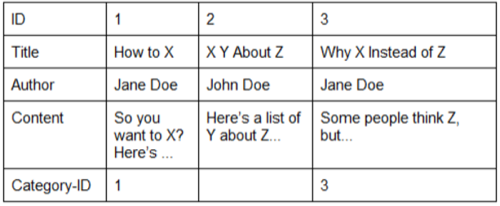
Because data stored in a column-oriented database is usually quicker for a DBMS to read, columnar databases are popular for data warehouses. Columnar databases are usually relational databases, but need not be.
SybaseIQ may have been the first columnar database. Columnar databases have been a hot property. In the past two years SAP acquired Sybase, EMC acquired Greenplum, IBM acquired Netezza, HP acquired Vertica and Teradata acquired AsterData.
Distributed Database
A distributed database spreads data across multiple disks on multiple servers. Wikipedia describes some of the key challenges:
“To ensure that the distributive databases are up to date and current, there are two processes: replication and duplication. Replication involves using specialized software that looks for changes in the distributive database. Once the changes have been identified, the replication process makes all the databases look the same. The replication process can be very complex and time consuming depending on the size and number of the distributive databases. This process can also require a lot of time and computer resources. Duplication on the other hand is not as complicated. It basically identifies one database as a master and then duplicates that database. The duplication process is normally done at a set time after hours. This is to ensure that each distributed location has the same data. In the duplication process, changes to the master database only are allowed. This is to ensure that local data will not be overwritten. Both of the processes can keep the data current in all distributive locations.”
ACID Compliance
ACID, in this case, stands for “atomicity, consistency, isolation, durability.” These are the properties set down by computer scientist Jim Gray in the 70s as the essential to having a reliable database.
Here’s a perhaps oversimplified explanation of each component:
- Atomicity means that each transaction is a “thing” in and of itself. If one part of the transaction fails, the entire transaction fails.
- Consistency means that a database should stay in a consistent state from transaction to transaction. If a transaction fails, the database should be reverted to a pre-failure state, deleting all traces of the failed transaction.
- Isolation means that data that is being modified during a transaction can’t be accessed or modified until the transaction is over.
- Durability means that data is safe from various sorts of failures. A user shouldn’t have to worry about a failed transaction causing data from previously successful transactions to be lost.
As we’ll see later, these principles are difficult to maintain in distributed databases without making other sacrifices.
Sharding refers to partitioning a database into multiple interdependent parts, typically to enable the creation of a distributed database. Sharding is used on row-oriented databases to split them up by row. Shards might be created based on a logical grouping, for example a sharded blog database may split the blog post table up by author. You can learn more about sharding, and some of the challenges it presents, here.
In-Memory Database
An in-memory database stores data in its RAM instead of on a disk. Reading from and writing to RAM is much faster than working with disks, but typically computers have far more disk storage than RAM. For example, the computer I’m writing this on has 4GB of RAM, but 500GB of hard disk space. Servers tend to have similar proportions. What this means is that you’ve either got to have enough RAM on a single server to run your software and store your data sets in memory, or you’ve got to distribute your data over multiple machines.
The other problem with in-memory databases is persistence. What if the DBMS crashes, or if the computer running it is turned off unexpectedly? There are various ways that in-memory databases or other in-memory data systems backup data to disk for such cases. We won’t go into that here.
Database Caching
Remember our example from the Relational Database section of Part One? Every time we pull up a blog post, the DBMS has to find the data from each column and assemble it into our blog post. On a busy site, this can create a burden on the server. If the database isn’t updated too often (by “often,” we mean every few seconds, or even multiple times per second), you could “cache” all the data from from those columns so that every time you pull up a post, you have all the columns assembled already. A cache, in this case, is essentially a snapshot of the query we want.
Memcached is a program that caches data in-memory, which can speed-up a disk-based RDBMS considerably. It was originally created at Live Journal and is now used by sites ranging from Reddit to Zynga to speed up sites and reduce the load on servers.
Next: NoSQL and NewSQL
In the third and final section we’ll talk about non-relational databases (also referred to as NoSQL databases) and the emerging category of data stores referred to as NewSQL. Watch for it tomorrow.
Special thanks to Tyler Gillies for his help with this series

















