Big Data is not new. For decades companies have been leveraging massive data warehouses and other proprietary Big Data tools to optimize business processes, improve customer targeting and more. That, however, was the problem: proprietary. Today Big Data is so big precisely because it’s so open: Hadoop, NoSQL databases and all other leading Big Data technologies are open source. Without exception.
As such, for the first time enterprise users of Big Data technology are the primary winners in the market, rather than the vendors who serve them. That’s the open source effect on Big Data, and it’s only going to accelerate over time.
Hadoop’s Unfair Advantage
Though just one of many winning open-source projects, Hadoop is perhaps the poster child for Big Data technology. While Hadoop enables a new class of analytics, arguably it’s earliest innovation was to dramatically lower the cost of storing and analyzing huge quantities of data.
Most simply, Hadoop took analytics workloads off expensive, proprietary hardware and enabled them on cheap, commodity hardware.
Importantly, as much as 95% of enterprise data is unstructured, which the old world of relational Big Data infrastructure can’t easily manage. Hadoop and NoSQL databases are perfect for such data, however, and so enterprises have been embracing both at a frenetic pace.
This democratization of Big Data technology is so critical that enterprises have been willing to overlook some of Hadoop’s growing pains. A full 26% of Hadoop’s most sophisticated users acknowledge that its complexity is holding back broader adoption.
And yet Hadoop rolls forth, expanding at a compound annual growth rate of 60%.
The Elephant In the Room For Legacy Incumbents
The results haven’t been kind to proprietary vendors. As The Wall Street Journal recently noted, Hadoop and other open-source Big Data technologies are having a serious deflationary impact on Oracle and other proprietary data infrastructure companies. It’s the “elephant in the room,” and it’s only getting worse for legacy vendors.
Mike Olson, chief strategy officer at Cloudera, identifies why open source is essential to Big Data innovation, and why no proprietary vendor can hope to compete:
[T]he economics of free to download, free to install and free to use combined with the faster innovation from the broader community that the open source community creates, compared to any single vendor, is just not a fair fight.
[Why? Because] all the smart people work someplace else. No matter how good you are at hiring, there are people in Uzbekistan that are beyond your reach. Add the fact that not just me and my company can figure out the right thing to work on. The entire planet with lots of innovative minds all over the place can direct their attention to their problems to enhance the platform in particular ways to make their life better. The aggregate benefit is that it is just not a fair fight.
Not that Cloudera, Hortonworks or any of the other Big Data companies are planning to tie one hand behind their backs in this fight. They’re going up against decades worth of incumbency.
A Booming Market Built On Free
Despite free downloads and cheap hardware, the Big Data market is booming. Primarily built on Hadoop and NoSQL databases, the market is projected to hit $3.4 billion in annual revenues by 2017, according to Wikibon research:
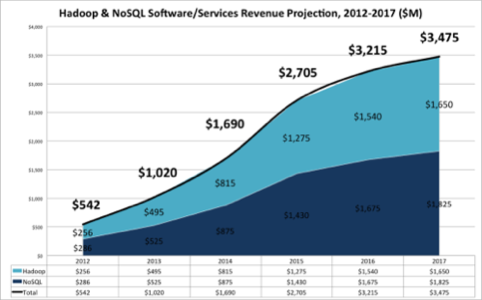
That’s a lot of money, but it doesn’t quite capture the value that Hadoop and other open-source Big Data technologies generate. As open-source software, much of the value is “lost.” Lost to vendors, that is, but not lost to those that matter most: organizations that want to put their data to work.
All of which leads Olson to make a compelling point: “You want to get rich on Big Data? Use it!”