In a previous article, we discussed the Web of data, which is about inter-linking open data sets and, thus, turning them into machine-accessible structured data. In this post, we’ll draw a picture of how the emerging social Web could serve as a Web of identities, which is essentially a people-data version of the Web of data.

W3C’s
The LOD approach is very good for static and encyclopedic knowledge, but what about accessing our personal data? Technically, modeling our identity, profile data, social graph, groups, activity stream, assets, and other kinds of personal data is straightforward. But empowering machines to access this data could present challenges to the LOD approach, because it comes with all sorts of constraints and peculiarities, such as privacy and data volatility. People want control over who has access to their data or parts of their data and want to be able to block access for any reason. And issues such as rapidly changing and outdated data remain unaddressed.
This is where the social Web can help.
There was a time when we had to create a new digital identity for each social application we wanted to use. A social application provides features based on social attributes. Every application provider implemented its own proprietary ID management to authorize users to log on and implemented its own proprietary user profile system to manage information about its users. Application providers were judged by the size of their user and content base and so erected endless walled gardens to protect their properties.
The most significant issues people had were:
- Low conversion rate for user registration,
- Users had to register for many accounts,
- Users had to re-enter and synchronize profile data,
- Privacy, data ownership, and inability to export.

Not much has changed, unfortunately. Most remarkable, perhaps, is the growing number of single sign-on (SSO) solutions that address the first issue for application providers and the second issue for users. New application providers can now outsource this functionality to a third-party SSO provider. Some of the biggest application providers became ID providers themselves to allow their users to log on to third-party applications with the same ID, and this has gained traction beyond these few providers. This has led us to an era of identity wars between the big providers.
Many ID providers, such as Google, Yahoo!, MySpace, and Facebook, have added the OpenID SSO to their own proprietary mechanisms over time. Because of the open nature of OpenID, many third-party providers have found it easy to integrate with the bigger providers, giving them more traction because users are able to access their services so easily using their OpenID credentials. Now, these ID providers can offer read-only access to fragments of profile data that users can look up or copy to third-party applications. Like SSO and OpenID, this began with proprietary solutions, but now exchange formats and protocols are emerging whose open language allows applications to easily exchange and synchronize data. These include:
- API access authorization protocol OAuth,
- Social graph exchange format FOAF (“friend of a friend”),
- Updates exchange format activity streams,
- Address book exchange format Portable Contacts.

In the future, ID providers will loosen their connection to social applications and start taking over management of users’ social attributes. Users will be able to log in to applications using credentials hosted by their ID providers of choice and grant permissions to these applications to read or even sync selected fragments of their profile data. The borders of these walled gardens will thus blur, and the social Web will become more of a weave than a patchwork quilt.
The Web of Identities
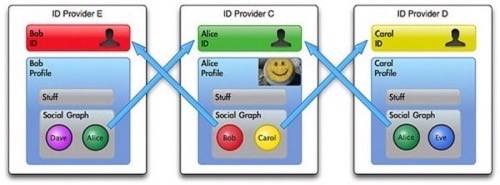
The Web of data is a distributed web of interconnected sets of semantically annotated data. A connection is achieved as a result of data pointing to data contained in another set through a URI, just as websites point to each other with URIs. This way, machines can crawl the sets to read the data. ID providers will most likely refer to their users via URIs in the future as well. A social connection will consist of one user’s URI pointing to another user’s URI or ID provider. If permitted by users, a machine may very well accomplish its tasks by jumping through the Web of identities from user to user, the way it does through the Web of data.
Why is this needed? The Web of identities is actually a super-social graph that spans multiple ID providers. If we come across walled gardens, this infrastructure would be needed for all of the social-related search functions we perform. The following examples are thus far provided only (if at all) within individual applications:
- “What is the best book read by friends in my circle?”
This query might retrieve book purchases and book-related status updates that your friends have made accessible through their privacy settings and then rank the books in a set. - “Notify me if a close friend visits Berlin.”
This permanent task repeatedly looks up your friends’ geo-locations. You may also have granted your close friends access to this data, too. This task could even be combined with the Web of data to look up the meaning and location of Berlin. - “Sync my address book.”
This permanent task continually synchronizes my friends’ addresses and numbers with my personal address book.
Now it’s your turn. In what ways do you think the social Web and Web of identities are evolving?
(Diagrams by alexkorth)

















