In the coming years, we will see a revolution in the ability of machines to access, process, and apply information. This revolution will emerge from three distinct areas of activity connected to the Semantic Web: the Web of Data, the Web of Services, and the Web of Identity providers. These webs aim to make semantic knowledge of data accessible, semantic services available and connectable, and semantic knowledge of individuals processable, respectively. In this post, we will look at the first of these Webs (of Data) and see how making information accessible to machines will transform how we find information.

The amount of information and services available is growing exponentially. Every day, it is getting harder to find the information we are actually looking for. Still, we have to learn how to tell machines what we want. Why can’t a machine understand which website, recent tweet, Flickr photo, Facebook message, or restaurant we are currently looking for?
Because it can’t. It does not understand. It has no access to most sources. It lacks the semantic understanding and common sense to build bridges between information.
It is critical that machines gain a new level of understanding. Instead of statistically computing how well a search term matches a document, a machine must literally be able to understand. Therefore, knowledge bases are needed to look things up. Examples of these knowledge bases include:
- an encyclopedia containing knowledge to look up the semantic meaning and context of a particular term (e.g. to understand that Berlin is a city, how many people live there, and where it is),
- Yellow Pages or a service pool to query often-changing and more complex information (e.g. a route from Berlin to Porto by car, or the current temperature of Porto in Celsius),
- a people database to look up profile information, with user permissions, which could improve personalization and recommendations.
The Web of Data
The idea of the Web of Data originated with the Semantic Web. People tried to solve the problem of the inherent inability of machines to understand web pages. Initially, the aim of the Semantic Web was to invisibly annotate web pages with a set of meta-attributes and categories to enable machines to interpret text and put it in some kind of context. This approach did not succeed because the annotation was too complicated for humans who had no technical background. Similar approaches, like microformats, simplify the markup process and thus help bootstrap this chicken-egg problem.
These approaches have in common the effort to improve the machine-accessibility of knowledge on web pages that were designed to be consumed by humans. Furthermore, these sites contain a lot of information that is irrelevant to machines and that needs to be filtered. What is needed is a knowledge base for machines to look up “noiseless” information. But wait! Who said that machines and us humans need to share one web anyway?
The idea of the Web of Data came about as a result of both this limitation and the existence of countless structured data sets distributed all over the world and containing all kinds of information. These data sets are the property of companies that trend to make them accessible. Typically, a data set contains knowledge about a particular domain, like books, music, encyclopedic data, companies, you name it. If these data sets were interconnected (i.e. link to each other like websites), a machine could traverse this independent web of noiseless, structured information to gather semantic knowledge of arbitrary entities and domains. The result would be a massive, freely accessible knowledge base forming the foundation of a new generation of applications and services.
Linking Open Data
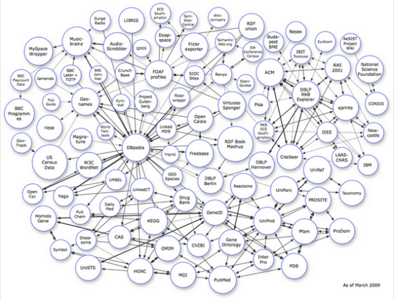
One promising approach is W3C’s Linking Open Data (LOD) project. The above image illustrates participating data sets. The data sets themselves are set up to re-use existing ontologies such as WordNet, FOAF, and SKOS and interconnect them.
The data sets all grant access to their knowledge bases and link to items of other data sets. The project follows basic design principles of the World Wide Web: simplicity, tolerance, modular design, and decentralization. The LOD project currently counts more than 2 billion RDF triples, which is a lot of knowledge. (A triple is a piece of information that consists of a subject, predicate, and object to express a particular subject’s property or relationship to another subject.) Also, the number of participating data sets is rapidly growing. The data sets currently can be accessed in heterogeneous ways; for example, through a semantic web browser or by being crawled by a semantic search engine.
To get a feeling of how this machine Web of Data feels like, you may want to look up:
- the company Yahoo! on CrunchBase,
- the city of Berlin or the game Tetris on DBpedia,
- the book iPhone: The Missing Manual on O’Reilly Media.
With every fact available on the Web of Data, more general and specific knowledge is made accessible to machines that will enable a whole new generation of services to be created. Highly sophisticated queries become machine-processable and accessible to the next generation of, say, search services.
Check out Tim Berners-Lee’s talk at TED about the Web of Data. How do you think about it? Do you encounter the same issues being overloaded by information or too much noise?
(Photo by zorro-art. Graph by the Linking Open Data project.)

















