I’ve been following a fascinating 3-part series of posts this week by Greg Boutin, founder of Growthroute Ventures. The series aimed to tie together 3 big trends, all based around structured data: 1) the still nascent “Web 3.0” concept, 2) the relatively new kid on the structured Web block, Linked Data, and 3) the long-running saga that is the Semantic Web. Greg’s series is probably the best explanation I’ve read all year about the way these trends are converging. In this post I’ll highlight some of Greg’s thoughts and add some of my own.

Web 3.0: What Comes After 2.0 (!)
Part 1 of Boutin’s series was about how Web 3.0 will not solve the vexing issue of Information Overload, at least not yet, because there is so much groundwork to lay first. Specifically, there is a lot of unstructured data on the Web right now; and it’ll take a lot more sorting out before it gets to be structured.
Last year Boutin loosely defined web 3.0 as “the Web of Openness. A web that breaks the old siloes, links everyone everything everywhere, and makes the whole thing potentially smarter.”
There is a lot of debate about what Web 3.0 is and the term itself is open to derision. In my view Web 3.0 is an unoriginal name for the next evolution of the Web. What’s important to note though, is that there is a difference in the products we’re seeing in 2009 compared to the ones we saw at the height of ‘Web 2.0’ (2005-08). If Web 2.0 was about user generated content and social applications such as YouTube and Wikipedia, then Web 3.0 is about open and more structured data – which essentially makes the Web more ‘intelligent’.
The smarter the data, the more things we can do with it. The current trends we’re seeing today – filtering content, real-time data, personalization – are evidence that ‘Web 3.0’ is upon us, if not yet well defined. We actually saw a great example of Web 3.0 this week, with Google’s release of Search Options and Rich Snippets. Those features added real-time search, structured data, and more to Google’s core search.
Linked Data: Structured Data, But Not Necessarily Semantic
In Part 2 of his series, Greg Boutin tackled Linked Data. He explained that “Linked Data offers a new medium to link structured data that is then more machine-readable.” However, he added that Linked Data “does not by itself add any semantic meaning to the information, but it better carries that semantic information once you have it. So, while Linked Data is not semantic, creating links at the data level paves the way to a true Semantic Web.”
Alexander Korth wrote a guest post on ReadWriteWeb recently that explains Linked Data more. It is a concept that comes from the W3C, which has a Linking Open Data (LOD) project. The image below illustrates participating data sets as of March 2009. Some of the more well-known commercial data sets are Thomson Reuters’ Open Calais project, Freebase, and DBpedia. As Alexander explained, the data sets are set up to re-use existing ontologies such as WordNet, FOAF, and SKOS and interconnect them.
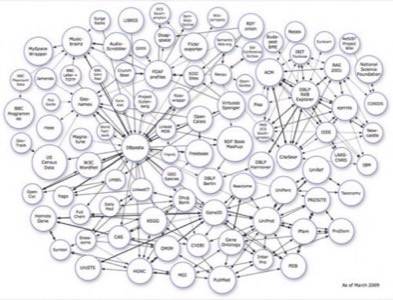
According to Greg Boutin in Part 3 of his series, the Linked Data format “does not create smart data, it only enables it.” He suggests that “technologies to turn unstructured data into structured data is really where we ought to invest, and focus our efforts.” Another piece of advice he gives is that entrepreneurs would do well to “consider mashing up Linked Data with other technologies.”
Semantic Web: Google Will Play a Big Role
So where does all of this leave the Semantic Web, that great white whale of the Internet? Boutin referenced a ReadWriteWeb post from October ’08, that asked Where Are All The RDF-based Semantic Web Apps? And that is the crux of the problem with the Semantic Web. While Tim Berners-Lee claims that the Semantic Web is open for business, the reality is that there are precious few real-world apps that use RDF currently.

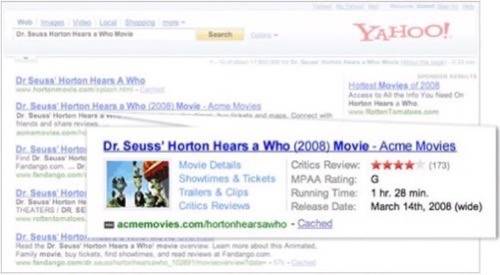
However RDFa, which enables web publishers to embed RDF into HTML, gives some hope. Google announced this week that it will support RDFa in its “rich snippets”, following on from Yahoo’s brave Search Monkey launch last year (which did a similar thing).
Google is going to play a big role in making the Semantic Web mainstream. We noticed here on ReadWriteWeb in January that Google had begun to expose semantic data in search results. We noted that Google appeared to be parsing the semantic structure from semi or unstructured data. An anonymous commenter in Boutin’s third post claimed that he’d published a similar finding 6 months prior to us – he said that “Google’s algorithm [is] a lot more sophisticated than just statistical methodology and that it was definitely already developing semtech knowhow and capabilities [in mid-08].”
Google isn’t the only big company doing this either. We’ve already mentioned Yahoo, but Microsoft paid over $100 million to try and do the same thing last summer when it acquired Powerset.
Conclusion
Web 3.0 is an amorphous term, and possibly one that people shouldn’t even attempt to use. Nevertheless, it’s clear to us that the time for structured data has come. We’re beginning to see it in the current wave of Linked Data sets being released, and in the support that big companies, like Google and Yahoo, are showing for structured data. Who knows, maybe the Semantic Web is nearly upon us too.

















