On Friday Radar Networks is announcing a new Semantic Web application called Twine. Founder Nova Spivack showed me a demo today of the new app, which he described as a “knowledge networking” application. It has aspects of social networking, wikis, blogging, knowledge management systems – but its defining feature is that it’s built with Semantic Web technologies. Spivack told me that Twine aims to bring a usable and scalable interface to the long-promised dream of the Semantic Web.

Spivack went as far as to claim that Twine will be “the first mainstream Semantic Web application” – and it’s certainly fair to say that we’ve heard lots of theory about the Semantic Web ever since Tim Berners-Lee defined it, but as yet there have been very few large scale success stories (if any). Will Twine finally be the Semantic Web app that breaks through? Let’s find out more…
First some background: Nova Spivack has an illustrious history in the Semantic Web and AI business, having worked for both AI legend Ray Kurzweil and tech guru Danny Hillis (Thinking Machines). The genesis for Twine, said Spivack, came from an R&D project about 5 years ago, which turned into a research project, then a Series A round with Microsoft co-founder Paul Allen in 2006. As of now the Twine team is 30 people working from San Francisco — and they’re finally ready to unveil their new mainstream Semantic Web product.
What is Twine?
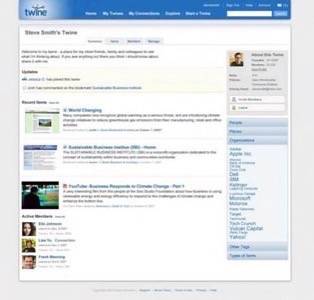
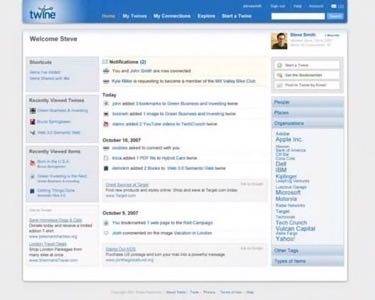
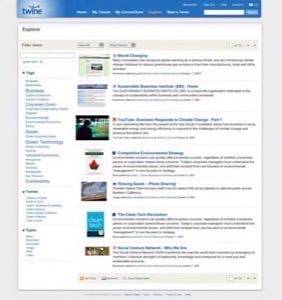
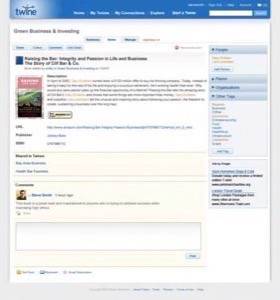
The aim of Twine is to enable people to share knowledge and information. At first glance it is very much like Wikipedia, but there is a whole lot more smarts to the system. Spivack described it to me as “knowledge networking”- i.e. it aims to connect people with each other “for a purpose”. It’s not based around socializing, but to share and organize information you’re interested in. Using Twine, you can add content via wiki functionality (there are many post types), you can email content into the system, and “collect” something (as an object, e.g. a book object). The screenshots below show of this in action — note that the product itself isn’t available just yet, as it’s in private testing.
Other features of Twine include: RSS feeds to track all kinds of things (topics, events, search, etc); commenting and viewing related things, sharing tags, and more. Also, and Marc Canter will like this, Twine users will be able to import and export their own data. Nova said that Twine will be an open platform – there will be a SPARQL API and a REST API.
Semantic Graph
Where Twine is differentiated from the likes of wikipedia is that its underlying data structure is entirely Semantic Web. Spivack told me that the following Semantic Web technologies are being used: RDF, OWL, SPARQL, XSL. Also he said that they plan to use GRDDL in the near future. Spivack had an interesting term for what Twine is doing with Semantic Web technologies, riffing off the Facebook Social Graph. Spivack is calling Twine a “Semantic Graph”, which he says will map relationships to both people and topics. So Twine’s Semantic Graph actually integrates the Social Graph. Spivack said that his company has patents pending on this.
Who will use it?
So who is Twine aimed at? Spivack said that it’s aimed at professionals and teams. Also he said content providers are expressing interest, because their data can be turned into Semantic Web data and re-used.
As for the business model, it will be advertising and also subscriptions (for higher capabilities). The advertising part won’t be in the first release and Twine hasn’t yet decided how to run that – e.g. they may use a single ad network provider, or (as Facebook is considering) create their own ad network.
Conclusion
Overall, while the app isn’t ready yet for the public, I was impressed with what I saw in Nova’s demo. The proof will be in the pudding regarding whether this will be the first mainstream Semantic Web app – i.e. how much uptake it gets and whether there will be good use cases for all this semantic data. But it certainly looked like a usable and slick system – and one I’m looking forward to playing with.
Screenshots
Click each picture to see full-length screenshots.