This week ReadWriteWeb will run a series of posts detailing what we think are the five biggest, most cutting-edge Web trends to come out of 2009. We’ll be posting one trend analysis per day. Then at the end of the week we’ll publish a major update to our standard presentation about web technology trends.

The first major Web trend we’re looking at is Structured Data. In prior presentations, this has sometimes been referred to under the umbrella term of ‘Semantic Web’. However the way 2009 has panned out so far, it’s become clear that this trend is much more than the Semantic Web. In this post, we’ll analyze the developments in Structured Data this year and provide you with 3 product examples: OpenCalais, Google, Wolfram Alpha.

Editor’s note: This story is part of a series we call Redux, where we’ll re-publish some of our best posts of 2009. As we look back at the year – and ahead to what next year holds – we think these are the stories that deserve a second glance. It’s not just a best-of list, it’s also a collection of posts that examine the fundamental issues that continue to shape the Web. We hope you enjoy reading them again and we look forward to bringing you more Web products and trends analysis in 2010. Happy holidays from Team ReadWriteWeb!
Web of Data, Not Documents
Tim Berners-Lee said in February this year that we’re now in a Web of Data, rather than a Web of Documents. The organization that Berners-Lee heads, the W3C, has heavily promoted two key initiatives that are helping to build this Web of Data: the Semantic Web and more recently Linked Data.
However over the past few years, we’ve seen that there are many other ways to structure data and enable others to build off it. The best current example is surely Twitter, whose API has historically been responsible for around 90% of Twitter’s activity – via third party apps.
The basic principle of the Web of Data is still the same as what Alex Iskold articulated on ReadWriteWeb back in March 2007: “unstructured information will give way to structured information – paving the road to more intelligent computing.”
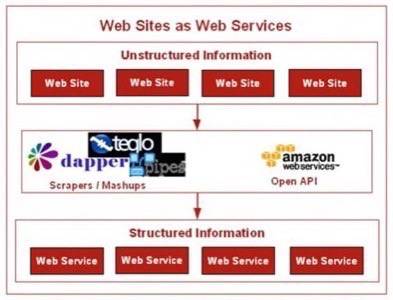
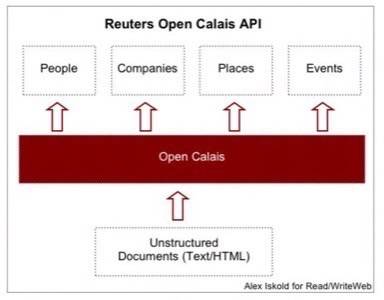
Example 1: OpenCalais
Our first example product, OpenCalais, is probably the best current example of Linked Data (which is a type of structured data endorsed by W3C). Thomson Reuters, the international business and financial news giant, launched an API called OpenCalais in Feb ’08. In a nutshell, OpenCalais turns unstructured HTML into semantically marked up data. It orders data into groups such as ‘people,’ ‘places,’ ‘companies’ and more. This way, third party applications and sites can build interesting new things from that data – one of the defining principles of Linked Data.

For a full explanation of Linked Data, read Alexander Korth’s technical introduction The Web of Data: Creating Machine-Accessible Information from April 2009. I also explained the background and benefits of Linked Data in a May ’09 post entitled Linked Data is Blooming: Why You Should Care.
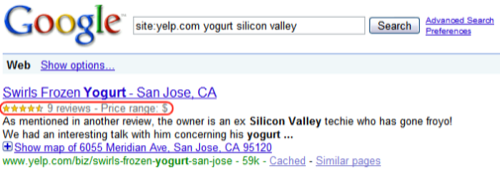
Example 2: Google Rich Snippets
In May this year, Google added structured data to its core search, in the form of a feature called ‘Rich snippets.’ Essentially this feature extracts and shows useful information from web pages, by way of structured data open standards such as microformats and RDFa. On launch in May, Google invited publishers to mark up their HTML. While it will take a while for this markup to become widespread, the fact that a huge company like Google implemented it shows the increasing importance of structured data on the Web.
Other big companies are also heading in this direction – in particular, Yahoo was an early leader.
Example 3: Wolfram Alpha
Ever since Wolfram|Alpha‘s much hyped launch in May, we’ve been tracking this innovative product closely. It’s a self-described “computational knowledge engine” and while it’s not quite the Google killer some predicted, it has many potential uses.

Wolfram|Alpha has a search engine-like interface, allowing you to type natural language statements into it. But the main part of the product is the computations you can do on data. The product is premised on using and computing data. If Web 2.0 was about creating data (a.k.a. user generated content), then the next generation of the Web is all about using that data.
Conclusion
We can see from the above three examples that structured data is rapidly becoming a feature of today’s Web. Companies like Thomson Reuters and Google are enabling data to be structured, and new types of products (like Wolfram|Alpha) will make use of structured data in ways we perhaps can’t imagine right now.
ReadWriteWeb’s Top 5 Web Trends of 2009:

















