An Interview With TweetDeck Founder Iain Dodsworth

A small startup company called InfoChimps released for sale yesterday three very large sets of data extracted from 500 million Twitter messages. Included in the offering are the senders and recipients of 1 billion @ messages, Retweets and Favorites. We wrote in-depth about the release late last night. This morning we interviewed Iain Dodsworth, creator of the most popular Twitter client, TweetDeck, about the value he might find in that data and the direction he’s aiming to take TweetDeck in the future.
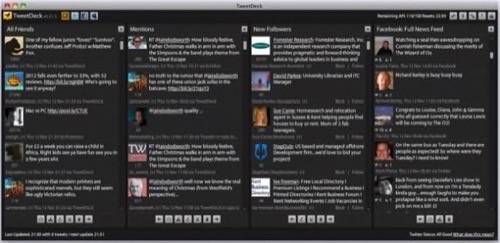
Dodsworth: Straight off the bat – an archive of tweets could form the basis of a profiler and that’s very interesting. Sentiment analysis (which I am ALL over) requires that kind of base corpus.
RWW: InfoChimps isn’t releasing full text yet, but they would do a custom slice if you wanted it.
Dodsworth: It’s the historical element that a large number of services are missing and where they will fall flat – analysis based on the last few hundreds tweets is almost pointless.
RWW: I’m curious what “a profiler” might mean to you and what this data could help make possible in those terms.
Dodsworth: For me a true profiler would be akin to the holy grail – we would analyse who a person converses with, who RTs them the most, essentially all interactions. Then we would track activity metrics (how many tweets sent, replies) and then we would analyse language patterns (usage of certain words) to ascertain how they express themselves and pinpoint sentiment. Off the top of my head this could lead to elements of intention prediction and I’m steering TweetDeck to have this kind of very very basic Artificial Intelligence at its heart.
I’m currently researching intent predicition inside high frequency trading systems and it’s fascinating and could directly relate to TweetDeck and social media systems/services in general.
[Dodsworth’s background is in developing for financial services, at places like Prudential Financial and PricewaterhouseCoopers.]RWW: What would intention prediction look like in this context? On twitter?
Dodsworth: At its most basic if TweetDeck could predict what the user was probably about to require next, based on current activity, then it could start to collate that data in the background – cross twitter/facebook/linkedin data for example. I’m looking at it right now from a cross-service data gathering perspective where our servers do the gathering and hopefully get around the issues of API limits for example.
This is based on future functionality we’re mapping out now which is a lot more complex than looking at someone’s profile or seeing how many RTs one of your tweets has.
I’m thinking the scope is full social graph rather than just twitter/facebook.
RWW: I guess I’m having a hard time imagining “what the user was probably about to require next, based on current activity, then TweetDeck could start to collate that data in the background – cross twitter/facebook/linkedin data for example” might look like. Like, if I’m looking at a person’s profile, I’d probably like to see their LinkedIn data?
Dodsworth: Good example…or see how a certain person you’re tweeting with right now stacks up against “similar” people you’ve spoken to – a box could pop up mid-conversation and give you a tonne of metrics on this person. How full of [crap] are they? Are they a social media guru? Would you be wise to tell this person anything sensitive? Based on previous language patterns, is the person you’re tweeting with right now probably lying? A bit out there but possible in theory.

















