The explosion of “big data” has prompted many people to ask the question “How will we store all this data?” And while cloud computing offers the promise of infinite scalability for storage, the Biocep R Project hopes to address two related questions associated with the growth of big data: “How will we analyze all this data?” and, more importantly, “How can we analyze it virtually?”

As the name suggests, the Biocep R Project is built on R, a free software environment for statistical computing and graphics that’s described as “the lingua franca of data analysis.” But despite its increasing use, R has several shortcomings in terms of standardization, usability and collaboration.
Science and Statistics, Virtually
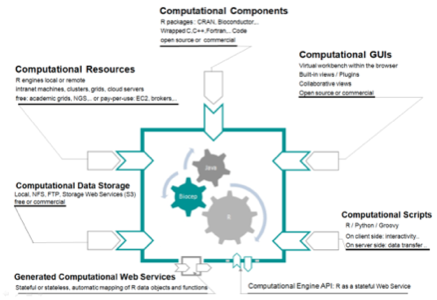
To address these shortcomings, Kalim Chime has created the Biocep R Project. It is an open source Java solution for integrating and virtualizing access to the R engines. Biocep provides a framework for access to the computational resources associated with R, but it also enables collaborative R sessions, with multiple web users connecting simultaneously to an R server. It also enables elastic computing across any number of virtual machines in order to solve complex statistical and analytical problems.
As Chime writes in a white paper on the project, “Biocep combines the capabilities of R and the flexibility of a Java based distributed system to create a tool of considerable power and utility.”
Using the Biocep R platform, Chime has also built Elastic-R, a portal that enables statisticians, financial analysts, students and so on to work with R engines and use their full capabilities from within simple browsers. A real-time cloud-based e-learning system, Elastic-R allows users to to share and reuse functions, algorithms, user interfaces, R sessions, and servers.
Open, Distributed Science through Virtualization
Using these tools, any number of geographically distributed users can collaborate simultaneously on scientific projects, using the same virtual machine, the same analytic tool, the same data.
As virtualization removes the requirements for local computational power and storage, perhaps we will see a more distributed, more open, and more participatory science as well, extending research and analysis beyond major research universities and computing centers.