There is some controversy floating around the blogosphere about the nature of the next web.
We got a clear signal from
Tim O’Reilly that there is no need to continue the versioning fad and call it “Web 3.0,” but still, people disagree about what’s coming next. To me, what is
coming is not a single thing, but a web that is characterized by several major themes.
Among the evolving aspects of the new web are Semantics, Attention
(Implicit Behavior) and Personalization. Regardless of what we are decide to call this next web, the
information in it is going to be more meaningful, more automatic, and more tailored to each of us.
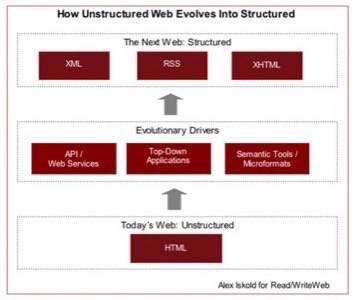
A critical piece of the next web evolution is the introduction of structured information. This concept is so basic to us as humans,
that we completely overlook the fact that it is quite foreign to computers. When a person looks at a book on Amazon, she sees
a book, with the author, ISBN number, publisher and the publication date. To a computer that page on Amazon is nothing more than
a bunch of HTML. Increasingly, information on the web is becoming more and more structured. This process is happening via
several major movements:
- The rise of APIs
- The proliferation of vertical applications that run on top of existing data
- An increase in classic Semantic Technologies and Microformats
- The spread of RSS as an information delivery mechanism
In this post we’ll look at how these movements collectively help power a more structured web.
The Basic Problem
To understand the basic issue with unstructured information consider the following example – a description of a book
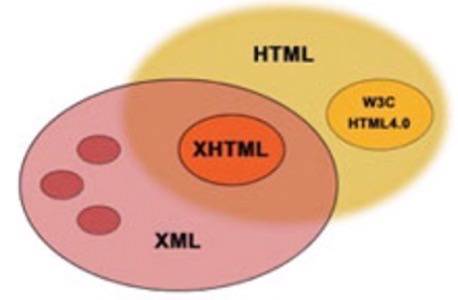
in HTML and XML. Here is a typical representation that you find if you look at the source of a web page:

Compare this with a representation typically found in XML:

The HTML does not capture the structure of the information, and mixes the information with the representation.
XML, on the other hand, is focused on structure only and does not say anything at all about how information should
be presented. Billions of web pages today contain unstructured information. To people, this is a non-issue because we are
good at semantics and we do not need primitive XML annotation to make us understand. But for computers, lack of structure is
a deal-breaker – they can’t interpret unstructured, non-standardized information very well.
Why Unstructured Information Is Bad
Way before people created the web, they created relational databases – the platform on which many corporations
and web sites are built today. A great thing about relational databases is that they represent the information in a structured way.
The query language know as Structured Query Language (SQL) supports fetching the information from a single database table.
More importantly SQL allows queries that correlate or select information from multiple database tables. Simply speaking,
SQL allows the data to be remixed. The only condition for this is that the data must be structured.
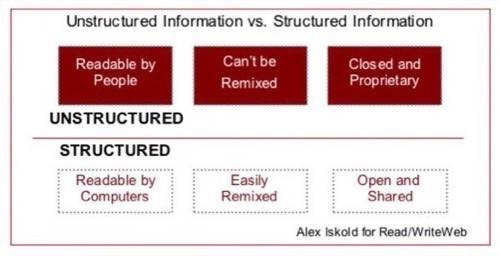
On the other hand, if the information is not structured, it is effectively stuck in a proprietary silo – closed and immobile.
Its representation is only understood by the creator, and it is not readily consumable by
any other application or a web service. In a way, this is sort of wasteful because it can not be remixed with the rest
of the information on the web.
The Key Drivers of Structured Information
1. The Rise of APIs. APIs are in fashion these days. Since del.icio.us, the web sites that have defined
the social web era have offered interfaces to access their proprietary databases. This effectively accomplishes two things.
First, APIs make it easy to fetch information. Second, most APIs these days emit the information
as XML, so it is automatically structured. For more about the impact of APIs on the web read our “When Web Sites Become Web Services” post.
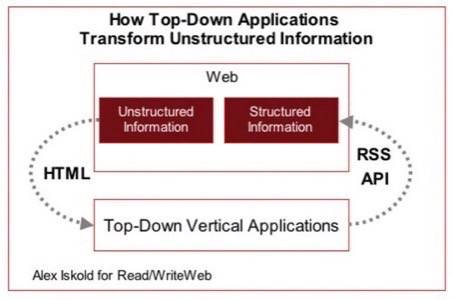
2. Top-Down Semantic Applications. We’ve written recently about the proliferation of top-down semantic applications.
In addition to creating utility by extracting meaning from content, these applications do another very important thing:
they automatically transform unstructured content into structured information. It happens because after extracting the info, the
services offer an API or structured RSS feeds, effectively injecting the structured information back into the web.
3. Classic Semantic Technologies and Microformats. The main goal of the Semantic Web is to make information structured. XML-based languages like RDF and OWL are designed
to capture information so that not only things, but also their attributes and the relationships between them, are represented clearly.
The classic approach, however, is running into many difficulties.
People are enthusiastic about the prospects and theory behind it, but lack of consumer focus and business value, as well as technical difficulties, have
made the implementation of classic ideas elusive.
In the mean time, microformats, a more simple approach to information annotation, has gained some momentum. The idea behind microformats
its simple: embed markup that indicates the structured information within HTML pages. What’s good about this approach is that
annotations are compact and can be interpreted by web browsers as well as any other program that reads the HTML page.
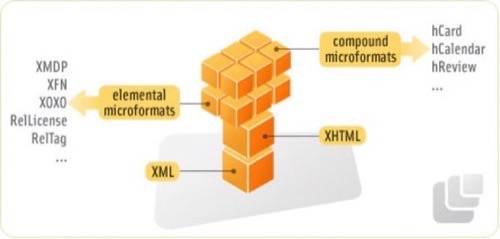
The approach also has issues, though. First, the number of things that can be described by microformats is limited. A popular microformat is
hCard, which describes contact information about people, organizations, and places.
The diagram above is from the Microformats web site.
A bigger issue revolves around how microformats are intended to be used. According to the designers, they are not
a new language, not infinitely extensible and open-ended, nor are they made for defining the whole world. Rather, microformats are an evolving solution, initially
aimed at designers as a “set of simple open data format standards that many are actively developing and implementing
for more/better structured blogging and web microcontent publishing in general.” Despite its simplicity, microformats are doing a lot of public
good by adding structure to unstructured content and pushing the envelope along with other solutions.
4. RSS As A Delivery Mechanism. There is a common misconception about RSS – people think that it is a structured language. It is not. Basic RSS
is a simple format for delivering news. Each RSS entry contains a title, a link and a description. In addition, RSS allows flexible embeds to deliver things like images, video and podcasts.
However, what is true is that RSS, like the XML language, is extensible. What has been happening is that companies have started using
RSS extensions to deliver results from their APIs. For example, as we’ve written,
Wine.com does exactly that – its API calls return RSS.

What does this mean? In addition to the standard RSS attributes, Wine.com outputs proprietary ones like id, sku and price.
Any application that would like to interact with this API can leverage the additional attributes. It is likely that companies will continue to use
RSS like this in the future. That’s because
RSS is already well known and the bottom line is that it doesn’t matter what XML-based language we use.
Technically speaking, any RSS extension is just XML and does not really have much to do with RSS. But if the world wants to think
that it is RSS and is willing to agree on a standard – so be it!
The Big Picture
So what happens if we take all of this and put it together? Something really profound – a structured web.
Possibly a precursor to the Semantic Web, the structured web would be much more readily remixable. It truly will be
the web as a database. Yes, a good old relational database, but instead of tables we would be remixing web sites and web services.
Probably the most interesting thing to note about the structured web of the future is that it will still be non-standard.
Just because information is represented as RSS or XML does not mean that two different services will have the same representation of a book.
However, the problem of mapping one representation onto another is generally not difficult, as long as the information is structured
(financial companies have been doing this for decades). So structure promises to bring nearly automatic interoperability.
Another outcome, is that the web where information is structured is much more amicable to be transformed into what is
currently envisioned as the Semantic Web. The ontologies and relationships are much more readily overlayed on top of structured information.
Likely, RDF and OWL would be used to do just that, as they were originally intended, except on top of the new structured layer.
Then the coming next web becomes a direct precursor to the Semantic Web. The leap of faith that
we are now being asked to make would disappear, and instead, the jump to semantics becomes obvious.
Conclusion
The next web is not just about one thing, its about many themes. However, what is fueling the web of the future is structured information.
As we discussed in this post, many different technologies, in their own way, are gradually transforming the web from its current HTML chaos
into a structured XML heaven. It has already happened in quite a few places and over the next few years we will be seeing more and more
structured information online.
The benefits? We hope that some of the promised semantic tools will be able to take advantage of the structured information.
We look forward to smarter search, and mashups that bring us exciting remixes that were not possible in yesterday’s world of
unstructured HTML silos.
If you enjoyed this article, please digg it here:

















