If you were to give a moment’s thought to the question of what’s keeping high-volume storage centers — especially the ones with cloud architectures — from replacing their multiple, redundant disk arrays with memory, you’d have time left over after you’d concluded the answer was cost. But what if the cost differentiator was getting smaller every year? Would there be a point in time, in the foreseeable future, where the practical costs of running a data center made purely of DRAM would be equivalent to one that uses traditional disk arrays?

A study just released by Stanford University (PDF available here) has come to the incredible conclusion that we may already be crossing that threshold today.
If you factor into the equation the principle that the cost of storing data to any medium increases as the reliability of that medium decreases, as a team led by Stanford University computer science professor John Ousterhout has done, you may conclude that a big bank of DRAM (no, not flash, but volatile memory) would be less expensive to acquire and maintain over a three-year period for less-than-huge data sets (in other words, not Twitter-sized) than a big array of disks for the same purpose.
What Prof. Ousterhout’s team has done is apply the lessons learned from modern private cloud operating systems such as OpenStack with respect to storage arrays, to memory. The first is to stick with cheap, readily available “commodity” parts. The second is to presume that such parts are prone to failure, so you plan for massive redundancy — because several components rarely fail at exactly the same time.
The rule the Stanford team cites that leads directly to their conclusions is referred to as “Jim Gray’s Rule,” although many hardware designers know it as “the five-minute rule” (Queue magazine page available here). The rule is named for researcher Jim Gray, who last served at Microsoft before becoming lost at sea in 2007. In 1987, the Gray Rule applied to whether a frequently accessed element of data should be maintained in a memory cache or written to disk. Its basic principle is, within a five-minute window, data that’s accessed very frequently can and should be stored in memory.
In a modern context, as the Ousterhout team explains it, the Gray Rule looks like this: “If portions of the disk are left unused then the remaining space can be accessed more frequently. As the desired access rate to each record increases, the disk utilization must decrease, which increases the cost per usable bit; eventually a crossover point is reached where the cost/bit of disk is no better than DRAM. The crossover point has increased by a factor of 360x over the last 25 years, meaning that data on disk must be used less and less frequently.”
A chart representing which storage technology has the lowest overall cost of ownership for varying dataset sizes and frequency of access. [Courtesy Stanford University Computer Science Dept.]
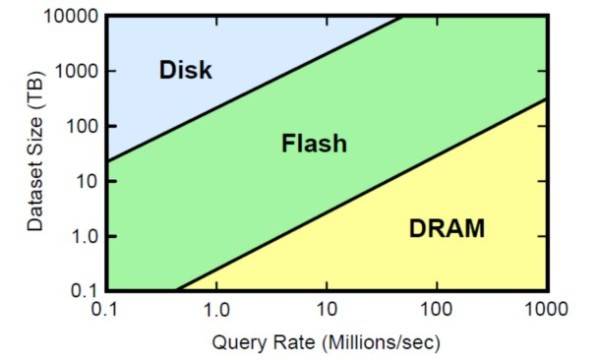
In a 20-year span of history, the size of the largest commercially available hard disks has expanded from 30 MB to 500 GB. Over that same span, the time required for a system to read an entire disk full of single-kilobyte (1 KB) blocks from edge to center has increased by a far greater factor, from five minutes to 30 hours. This points to an unavoidable problem with the physics of hard disk drives: While manufacturers can increase areal density with the net effect of reducing transfer rates, those sustained rates are only appreciated when reading very large blocks. The time to read a whole disk full of large blocks has only increased from 15 seconds for a 1987-era 30 MB drive to 1 hour 23 minutes for a modern half-terabyte drive.
Databases are not comprised of very large blocks; it’s these very small records where latency is introduced most often. And for so-called “NoSQL” databases that use vertical storage to improve logical access times, some of that speed gain is lost anyway due to latencies that simply are not replicated by DRAM.
The team’s stunning conclusion is this: “With today’s technologies, if a 1 KB record is accessed at least once every 30 hours, it is not only faster to store it in memory than on disk, but also cheaper.” The report goes on to say that, for that block to be accessible at the same rate on disk as in DRAM, the disk utilization rate must be capped at 2%.
Stanford’s name for a system that utilizes all-DRAM with controls based on cloud disk array techniques, is RAMCloud. (Insert Sylvester Stallone poster here.) The research team applied its results to a modern model of a typical online retailer, with $16 billion of annual revenue. At an average order size of $40, it probably processes 400 million orders per year. The maximum record size for an individual order is probably 10 KB. That means at most, it processes about 4 terabytes of orders per year, which is not anywhere near a Facebook-scale database.
A Stanford-style RAMCloud configuration for maintaining just that database over a one-year period (not counting other applications, VMs, and data) would cost that retailer about $240,000, by the team’s estimate.
“Numerous challenging issues must be addressed before a practical RAMCloud can be constructed,” the team concludes its report. “At Stanford University we are initiating a new research project to build a RAMCloud system. Over the next few years we hope to answer some of the research questions about how to build efficient and reliable RAMClouds, as well as to observe the impact of RAMClouds on application development.”

















