There has been quite a lot of buzz lately around a vertical search engine
for people, called Spock. While still in private
beta, the engine has already impressed users with its rich feature set and social
aspects. Yet, there is something that has gone almost unnoticed – Spock is one of the best
vertical semantic search engines built so far. There are four things that makes their
approach special:

- The person-centric perspective of a query
- Rich set of attributes that characterize people (geography, birthday, occupation,
etc.) - Usage of tags as links or relationships between people
- Self-correcting mechanism via user feedback loop
Spock’s focus on people
The only kind of search result that you get from Spock is a list of people; and it
interprets any query as if it is about people. So whether you search for
democrats or ruby on rails or new york, the results will be
lists of people associated with the query. In that sense, the algorithm is probably a
flavor of the page rank or frequency analysis algorithm used by Google – but tailored to
people.
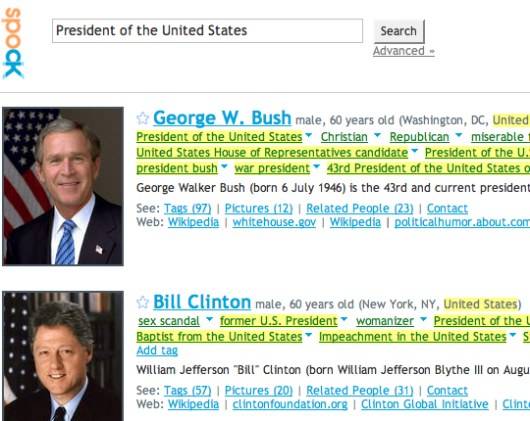
As a vertical engine, Spock knows important attributes that people have. Even in the
beta stage, the set is quite rich: name, gender, age, occupation and location just to
name a few. Perhaps the most interesting aspect of Spock is its usage of tags. Firstly,
all frequent phrases that Spock extracts via its crawler become tags. In addition, users
can also add tags. So Spock leverages a combination of automated tags and people power
for tagging.
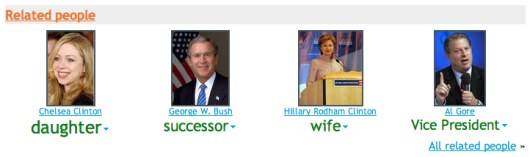
A special kind of tag in Spock is called ‘relationships’ – and it’s the secret sauce
that glues people together. For example, Chelsea is related to Clinton because she is his
daughter, but Bush is related to Clinton because he is the successor to the title of
President. The key thing here is that relationships are explicit in Spock. These
relationships taken together weave a complex web of connections between people that is
completely realistic. Spock gives us a glimpse of how semantics emerge out of the simple
mechanism of tagging.
Feedback loops
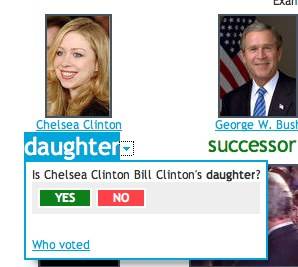
The voting aspect of Spock also harnesses the power of automation and people. It is a
simple, yet very interesting way to get feedback into the system. Spock is experimenting
with letting people vote on the existing “facts” (tags/relationships) and it re-arranges
information to reflect the votes. To be fair, the system is not yet tuned to do this
correctly all the time – it’s hard to know right from wrong. However, it is clear that a
flavor of this approach in the near future will ‘teach’ computers what the right answer
is.
Limitations of Spock’s approach
The techniques that we’ve discussed are very impressive, but they have limitations.
The main problem is that Spock is likely to have much more complete information about
celebrities and well known people than about ordinary people. The reason for it is the
amount of data. More people are going to be tagging and voting on the president of the
United States than on ordinary people. Unless of course, Spock breaks out and becomes so
viral that a lot of local communities form – much like on Facebook. While it’s possible,
at this point it does not seem to likely. But even if Spock just becomes a search engine
that works best for famous people, it is still very useful and powerful.
Conclusion
Spock is fascinating because of its focus and leverage of semantics. Using tags as
relationships and the feedback loop strike me as having great potential to grow a
learning system organically, in the matter that learning systems evolve in nature. Most
importantly, it is pragmatic and instantly useful.

















