Last week at the SemTech 2008 Conference that took place in San Jose, Yahoo! Researcher Peter Mika spoke in detail about the company’s new SearchMonkey search platform initiative. Mika talked broadly about his work looking at metadata on the web, and how that led to the birth of SearchMonkey. This post is based on notes from that talk.

History of Web Page Annotations
The motivating question for Mika’s presentation was: How can we make web search better by leveraging web annotation?
There are many kinds of annotations, but Mika focused on simple data and lightweight semantics, and began by reviewing the history and evolution of annotations to explain how we got to where we are today.
One of the first methods of annotating HTML was Simple HTML Ontology Extensions (SHOE). This method allowed for the declaration of ontologies as well as relationships between the entities on HTML pages. The problem with it
was that it introduced new tags that were not part of standard HTML and were not recognized by most browsers.
In 2003 Tantek Celik started work on Microformats –
a way to embed light semantics using XHTML. Microformats are now driven by a community of developers, which
evangelizes existing formats and is working on new ones. The major focus of this effort is to leverage standards,
but Microformats are limited because they don’t share common syntax. Every microformat
looks different and there are no ontologies, and no schemas.
Things get particularly complicated
when you start combining different Microformats, for example, when you describe that a person wrote a review
at a particular event. In addition to this, Microformats have no concept of unique identity, and for this
reason are largerly incompatible with other Semantic Web efforts. Yet, Microformats took off and have become somewhat widespread.
So, the take away here is that simple things can quickly gain adoption.
Another way of providing metadata that emerged recently is tagging. As an example, Flickr uses
tags for photos to enable its users to annotate and describe the content. The problem with tags is that there
is no agreement on meaning, so the same tag on Flickr and del.icio.us can mean different things, and there’s no way to be sure which tag means what. Tags are a much more personal way of annotating information; they are not objective.
In 2005, Ian Davis, CTO of Semantic Web infrastructure company Talis, proposed eRDF – a form
of RDF that can be embedded into HTML (compatible with HTML4). There is a simple mapping from
eRDF to RDF so you can use any RDF/OWL vocabulary. But eRDF is not full RDF — it has limitations.
For example, there are no data types and there no blank nodes. Also, each page can only “talk” about itself and not about other pages.
Finally, the W3C published RDFa the latest embedding of RDF in XHTML, which
has full RDF support. RDFa adds complexity in terms of implementation, but at the moment, gives the best way to embed RDF into HTML.
How Much Metadata is Out There?
Given the increasing trend towards web annotations, the natural question is, Just how much metadata is already out there?.
Peter Mika set out to answer this question and created a prototype, called Microsearch.
The idea was to look at web pages and to see how much metadata was there. Beyond that, Mika was also interested in what
type of metadata, as well as the ratio between annotated and plain HTML pages.
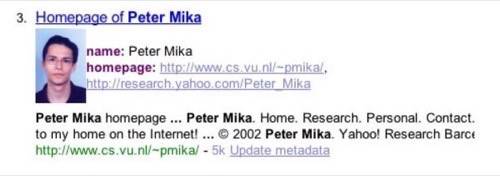
With the Microsearch exercise, Mika wanted to demonstrate what could be done to enhance search with this information. For each type of metadata, Mika
augmented search results with additional links and information. For example, maps, events, information from hCard, etc.
are presented in an enhanced way, unlike what we’re used to seeing with today’s search engines.

Mika discovered a few interesting things. First, about 53% of queries have 1 page with metadata in the top 10 results.
However, lots of the data Mika saw was not clean and contained information that was not well formed, and performance was pretty poor due to lack of an index. So the unfortunate conclusion that Mika came to was that RDF templating was difficult and the approach was not easily scalable. Finally, Mika realized that metadata really needs to be on the page for users to see,
because otherwise there is a big opportunity for semantic spam.
The Birth of SearchMonkey
The point of any experiment is to draw the right conclusions. Looking at the facts, Mika and the Yahoo! search team
realized that they could not count on enhancing search by leveraging metadata on today’s web – it simply does not exist to the extent needed. At the same time, it was clear that enhancing search results and cross linking them to other pieces of information
on the web is compelling and potentially disruptive. Yahoo! realized that in order to make this work, they need to
incentivize and enable publishers to control search result presentation. And thus, SearchMonkey was born.
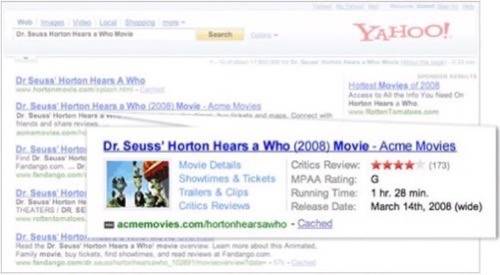
SearchMonkey is a system that motivates publishers to use semantic annotations, and is
based on existing semantic standards and industry standard vocabularies. It provides tools for developers to create compelling applications that enhance search results.
The main focus of these applications is on the end user experience – enhanced results contain what Yahoo! calls an “infobar” – a set of overlays to present additional information. For example, with SearchMonkey, LinkedIn is
able to surface additional information from the user profile, Netflix can present a blurb a about plot and a rating for a movie,
and Barnes & Nobles can embed a preview of a book.
SearchMonkey’s aim is to make information presentation more intelligent when it comes to search results by enabling the people who
know each result best – the publishers – to define what should be presented and how.
A Better Search Experience Ahead
This first version of Search Monkey is just the first small step towards creating a better search experience. Much more is planned, but even with this first simple version, we
can clearly see the power of semantics and annotations in web pages. By creating the right incentive for publishers and putting them in control, Yahoo! is aiming to up the bar on search results,
and, who knows, maybe even start attracting converts from Google’s plain-looking results.

















