While it has great potential, the Semantic Web has failed to live up to its promises so far. Part of the problem, as Thomson Reuters sees it, is that developers will not add a lot of semantic features to their products until publishers start publishing more semantic data. Reuters’ OpenCalais represents one way around this problem. But starting today, Reuters’ newest project SemanticProxy will give developers an easier way to extract semantic data from any web site.

Even though SemanticProxy is geared towards developers, Reuters has created a demo site that you can try out on the web by just copying and pasting the URL of any web page into a simple form. We tested it with articles on CNN, Wikipedia, and a number of blogs, and it always returned a highly relevant set of results (as long as the page was not excessively long). The service is optimized for performance on 30 of the world’s largest news sites, but it also works just as well for other sites.
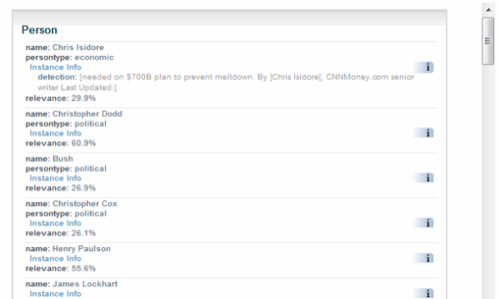
For a news story, for example, SemanticProxy will identify politicians, cities, countries, etc. that are mentioned in the article. Once parsed, the service returns the semantic metadata of the page in three possible formats: RDF, MicroFormats, or standard HTML.
As the name implies, SemanticProxy acts as a proxy and aggressively caches all its data, which should make it easy for a developer to scale a project that relies on this service.
Catalyst
SemanticProxy is part of Reuters’ attempt to jump-start the semantic web. As Tom Tague, the leader of the Calais initiative at Reuters, points out, SemanticProxy can hopefully act as a catalyst and get more developers to look at semantic data, which, in return, will give more developers a reason to publish this data themselves.
Disclosure: Calais is a RWW sponsor

















