We’ve all seen CAPTCHAs, those automated pictures of letters and numbers meant to foil spam bots. Some are more diabolical than others, but most are annoying. Now a team of researchers at Carnegie Mellon University have figured out a way to put them to use beyond aggravating users and confusing robots. Their idea: use them to help digitize books.

People decipher over 60 million CAPTCHA images per day, spending over 150,000 hours in an attempt to stem the tide of spam and keep automated bots from wasting the resources of web sites. That’s time the team at Carnegie Mellon thinks can be put to a good use. They’ve figured out a way to use CAPTCHAs to help digitize old books using a program they call reCAPTCHA.
There are many projects underway to scan old books and other texts into digital format, but Optical Character Recognition software often falls short, especially with oddly stylized text or old, faded works. When the computer can’t figure out a word, a human has to step in and enter it manually. This means reading thousands of digital images of words and deciphering them — or essentially what you do when you solve a CAPTCHA image.
The Internet Archive project scans 12,000 books per month and sends the team at Carnegie Mellon hudreds of thousands of images of words the computer can’t figure out, according to the Washington Post. These images are turned into CAPTCHAs for the reCAPTCHA program.
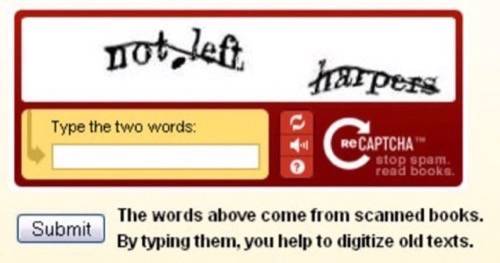
But if the computer doesn’t know the word, how will it know if the human entered it properly? The reCAPTCHA program gives users two words to decipher: one which it already knows, and one which is a mystery. Employing a certain level of trust, the computer assumes that if the user correctly identifies the word it knows, then he probably figured out the one it doesn’t correctly as well.
The reCAPTCHA tools are available to any website owner who wants to employ them. The program is written in Python, but libraries are available for developers in PHP, Perl, and Ruby as well, and there are premade plugins for WordPress, Movable Type, MediaWiki, phpBB, and Typo3. There is also a way to protect your email address with reCAPTCHA using Mailhide.

Conclusion
Though I am sure that some mistakes probably still slip through, this is a brilliant use of otherwise wasted time, similar to the SETI@Home or Folding@Home projects, which both employ down time for a useful pursuit (though there are some who would argue searching for E.T. isn’t useful at all, but I digress).
Back in college I took part in a project to digitize old maritime journals. Even using a very expensive high resolution scanner and top-of-the-line OCR software, half of our time was spent correcting mistakes the computer made. After a couple of hours staring at computer screens filled with garbled text and comparing it to musty old books, you started to get jaded and make mistakes.
If every website that uses a CAPTCHA image switched to the reCAPTCHA system, it could theoretically solve 60 million words per day. Even if you employed double or triple checking of new words (i.e., ran them through the system multiple times to make sure you got the same results back), that would go a long way toward the goal of digitizing all of the world’s information. I would suspect that Google might be very interested in the reCAPTCHA program (so far Intel, Novell, and the MacArthur Foundation have given their support).

















