Today’s big news is that Amazon’s S3 online storage service has experienced significant downtime. Allen Stern, who hosts his blog’s images on S3, reported that the downtime lasted3.5 over 6 hours. Startups that use S3 for their storage, such as SmugMug, have also reported problems. Back in February this same thing happened. At the time RWW feature writer Alex Iskold defended Amazon, in a must-read analysis entitled Reaching for the Sky Through The Compute Clouds. But it does make us ask questions such as: why can’t we get 99% uptime? Or: isn’t this what an SLA is for?

You can see the status as of writing in the screenshot below, taken from the Service Health Dashboard:
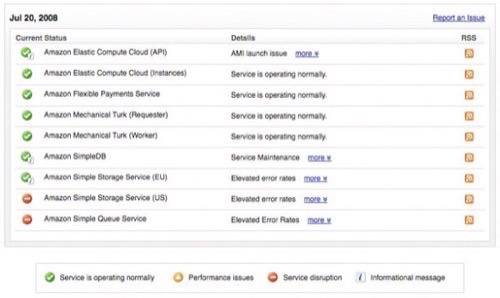
Interestingly, SmugMug – an online photo and video provider – doesn’t seem too concerned about the outage. It seemed almost blase about it in its blog post today:
“Historically, Amazon has been very stable. We’ve seen three of these in our entire history with Amazon (>2 years), including this one. I expect, like the last two, that service will be restored shortly. You can keep track of their efforts over on their own Status Dashboard.
Our faith in Amazon, and the care they take of your priceless memories, hasn’t been shaken. Your photos and videos are safe – which is our #1 concern. Since problems in this industry are inevitable, and Amazon’s performance over the last two years has been so exceptional, we’ve been afraid an outage like this. I’m sure there will be more over the next few years, too.
The important thing is that they’re few and far between, short, and handled properly. Every component SmugMug has ever used, whether it’s networking providers, datacenter providers, software, servers, storage, or even people, has let us down at one point or another.”
This almost exactly mirrors what Alex said in February. Cloud computing is a complex business, wrote Alex, and Amazon is simply the best available option:
“The truth is that we cannot do it better than Amazon. They spent a massive amount of money, talent and most importantly time, trying to solve this problem. To think that this can be replicated by a startup in a matter of months, assembled, be cost effective, and work properly is just absurd. Large-scale computing is an enormously complex problem, that takes even the best and brightest engineers years to get right.”
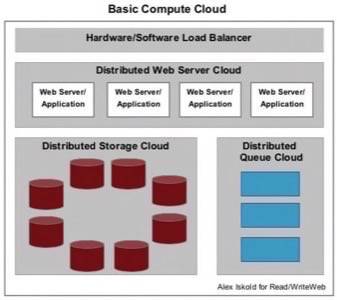
Here’s a diagram that Alex did to illustrate the concept of cloud computing:
I guess the answer to the question, how much is too much downtime, is: hey, whataya gonna do? (imagine that said in a New York accent and with a shrug).
What do RWW readers think: are these outages getting too much, or do you still cut Amazon some slack?

















