Because Twitter is getting more popular, every glitch in the service is now felt more acutely. Going without Twitter for many people is even harder than going without email, and so outages lead to complaints.
Complaints pile up and become debates, asking questions like: should Twitter be converted into a protocol and become decentralized? Is that the way to scale Twitter and make it more reliable? If not, how can that goal be accomplished?

To me, the answer to decentralization is a firm no. First of all technically it won’t solve the problem.
At least not in any way that Twitter folks can’t solve it themselves. The whole question actually misses the main point. We love
Twitter as an application, and its strength is the fact that people know where to find it, people love the What are you doing now?
question. Amongst a sea of copycats, it was Twitter that took off and that’s why we know and love it. Twitter is Twitter and it should not be anything else.
The question that people should be asking, though, is how to properly scale Twitter and, for that matter, the whole slew of
other life streaming applications. Clearly these applications are trying to break new ground by merging streams of your
friends’ activity together and presenting you with a single view of that information. All of these applications are facing similar challenges and they could all architecturally benefit from the same pattern. So what is it? How should these applications
be designed so that they scale to meet the demand?
What is the Problem?
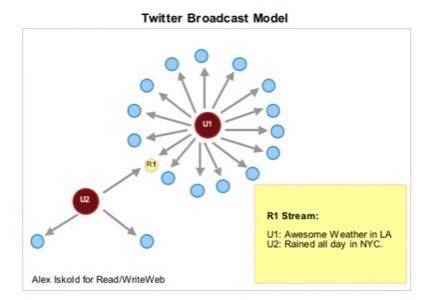
To understand the challenge facing Twitter and other life streaming applications look at the diagram below.
A node in the center is an individual user and the the nodes around it are the users that follow or subscribe to
this user. The blue nodes are subscribers and red ones, U1 and U2, are publishers in this diagram. The yellow node, R1, is
a receiver that gets updates from both U1 and U2. The yellow note shows that the stream of R1 contains updates
from both U1 and U2.
How to manage all of this is pretty obvious until one starts thinking about how to generate the stream for R1. The answer that
comes to mind right away is – on demand. That is, when the user R1 checks his Twitter page or via one of the many
Twitter clients, the stream is computed and delivered on the fly. Unfortunately, and this is true with distributed
large-scale systems in general, the first answer is likely to be wrong. If the user subscribes to say 100 other people,
to pull together 100 streams and merge them so that they are in the right time order is likely to take seconds if not
minutes. Who is going to want to wait this long?
If the user view can not be computed on the fly, then the only other answer is that it is
pre-generated. That is, whether the user checks or does not check the stream, it is there and available
as soon as possible. This answer also seems wrong, because this approach is quite wasteful. Pre-generating all these
views without anyone looking at them is going to cost a lot of wasted space and compute power. Yet, of the two approaches,
this is the one that delivers a better user experience and so this is the one that is likely to succeed.
Relational Database – Likely the Wrong Way
We wrote about scalability challenges with relational databases in our post about Amazon Dynamo.
Yet relational databases should not be dismissed. First, lets look at how relational database can be used to engineer a solution.
A simple approach is to have three tables USER, FRIENDS, and MESSAGES; the tables would look like this:
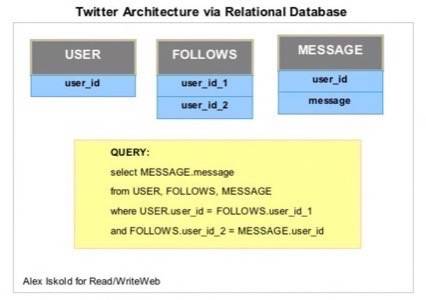
This is very simple, and of course it does not scale. As the tables grow, even if everything is indexed,
doing all the look ups via this set of tables can not work. What kills this solution is that all information
of all users is sitting in these tables. What if there was a way to split all this information into many databases?
If this was possible then the system would scale. So lets say we took all the users that start with letter ‘a’ and
put them into one database and then all the users that start with letter ‘b’ into another and so on. There are systems
that can benefit from such partitioning. For example, MyBlogLog can be partitioned so that all data is stored
around individual blogs.
Unfortunately, in case of Twitter and other life streaming applications such partitioning does not work. The reason is that
we can not predict who is going to follow who. So there is no way to cluster the data so that all the necessary
messages end up in the same database. And cross-database queries are very costly – not a way to go. So the reason a relational database does not work is because a single database system does not scale and the data is not amicable to partitioning into multiple databases.
Data and Compute Cloud – Possibly the Right Way
Increasingly more and more companies, particularly in the consumer space, are turning to cloud computing. The fundamental difference that the cloud approach takes vs. the relational database approach, is that with the cloud you split the data and split the computation on a massive grid
and then make trade-offs. For example, in the relational database data duplication is a big no. Things need to be normalized.
In the cloud world data duplication is okay, because a lot of views are pre-generated and a lot of them contain duplicate information.
For example, a message from one user is duplicated into bins for everyone who subscribes.
The second trade-off is consistency,
which is kind of related to duplication. When we are talking about mission critical applications on Wall Street, data consistency
is a top priority at all times. But does it matter if user A gets a message from user B and then it takes a few minutes to deliver the same
message to user C? Of course not. Even in our real-time hungry culture this delay is acceptable. So the trade-off is
to forgo consistency across the entire system but gain flexibility instead.
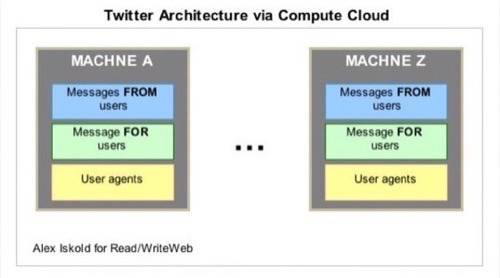
The cloud version of the system is depicted above. For simplicity we have 26
machines on the grid – one for each letter. Each machine is identical and focused on users whose id starts
with the corresponding letter. All information about a specific user is stored on the machine, including profile,
list of people who follow this user, etc. The key thing is that the system maintains not only a list of messages
generated by this user, it also immediately creates a list of messages for the user. It does that by processing
updates from other machines. The whole thing is a peer-to-peer, completely connected ring system, where each machine
is connected to all others.
When a user types an update into the UI it is first sent to the machine that handles this user. That machine immediately updates the user’s messages and then broadcasts those messages to other machines.
For each other user who follows the one that just updated,
the system constructs the message and sends it precisely to the machine that hosts that other user (it is known
because users are split based on letters). So for each update the system sends out exactly the correct number of messages.
Then as soon as the message is received on the other end, it is written directly into the stream of the receiving user.
What is nice about the cloud solution is that it scales as the user set grows. The partitioning mechanism does not
need to be based on letters, in fact it should really be based on a quick, uniform hash which would ensure that
the users are distributed evenly around the grid. And there are many other details, of course, because what we
described here is not the solution, but just the basic idea.
Conclusion
Software engineering as a discipline has evolved a set of design patterns. These
are solutions that work across languages and across different systems. What we need is new design patterns for life streaming applications like Twitter.
Instead of talking about breaking the service into distributed systems (which likely would perform worse and have more outages), we
need to work through the best ways of building this kind of software. Google scales, Amazon scales, and as Stowe Boyd pointed out, so does AIM
(although it has considerably less connections). And certainly there is a right architecture for Twitter, which would make it scale to meet the growing demand.
So lets start right now! Please tell us what you think are the best ways to design life streaming applications? What trade-offs do you think
should be made? And please tell us about your specific experiences building these systems.

















