Let’s say you are going to, or hosting, a conference and you want to make a good impression with the attendees and organizers. One way to do that is to create useful and thoughtful original content and resources regarding the event.

Thanks to tools like Mechanical Turk, Google Custom Search and of course Twitter, you can now do incredible things around conferences that would have been very inefficient to do before.
Earlier this month I went to the Techonomy conference in Lake Tahoe and wrote both here on ReadWriteWeb and on the conference blog. The event brought technologists together to talk about tackling the world’s big problems, like water and food shortages. It was a very impressive group of people. Before the event began, I used a few online tools to create some resources that proved very helpful in creating high-quality coverage of the event. I thought I would share what I did so that readers could make use of these same or similar methods.
Resources Created
Specifically, here’s what I set up:
- A Twitter list of all the conference attendees who use Twitter. This was very useful for keeping track of what people were saying during the event, even if they weren’t using the official hash tag. It’s also a really impressive list of people to keep in touch with in the future, and now when I’m viewing their Tweets in a list, I’ll always know the context that I discovered them in.
- A Twitter list of women participating in the event. I also did the research to make it easy for me to create a list of people from outside the United States who were there. It’s good to create a special view into the conversations of some groups of people who can get lost in the noise of known industry leaders, in this case disproportionately men from Silicon Valley. Those lists are good not just to track particular perspectives during the event, I’ve also subscribed to the same lists in the beautiful iPad app Flipboard, so now I’ve got a personalized magazine made up of all the links shared on Twitter by international attendees of the Techonomy conference. That’s nice to have.
- Most important for the blogging at the conference, I created a Google Custom Search Engine that searches the archives of all the websites of the organizations the conference attendees work for. This proved invaluable, as I could reference the previous work and research of the people present in writing about their discussions that weekend. It made for much better-informed blogging than I would have been capable of without the tool.
How To Get the Info
I created all of the above in one night, for $50.
Here’s how I did it.
First, and this is probably the least accessible part, but it’s not that hard. I asked ReadWriteWeb’s technical guy Tyler Gillies to scrape me a CSV (comma separated value) file of all the names and descriptions on the page listing the participants. “I used an html parser and searched for div tags with the class that matched participant,” he says. It was a Ruby parser he wrote himself and luckily the CSS of the page put participants in a nice div. That took a few minutes at most.
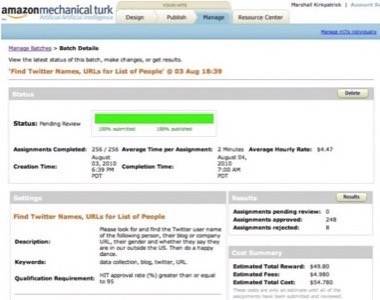
Next, I loaded up Amazon’s Mechanical Turk web application. Mechanical Turk is a system that allows you to break down projects into very small tasks and pay a human being a small sum for each task they complete.
I created a template in Mechanical Turk that basically said: “Look at this person’s name and description. Find their Twitter username, their organization’s blog or website, tell me if they appear to be Male or Female and whether they appear to work inside or outside the US. For each name you do this for, I will pay you 20 cents.” The end result was that I got all that info about 256 people very quickly, mostly in a few hours but 100% complete overnight, for just over $50. It was very much worth it.
Mechanical Turk takes a little bit of time to figure out how to use, but it’s not that hard. Basically, you build a template, then you upload a file to populate that template for each worker. It’s remarkably efficient.
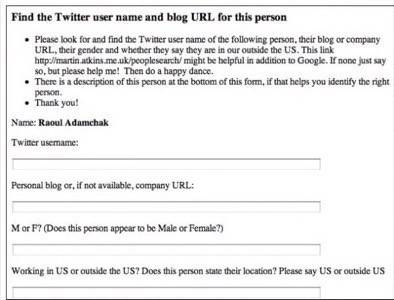
At that point it wasn’t hard to click through all the Twitter usernames and add people to one or more lists. It wasn’t hard to copy and paste the website URLs into Google Custom Search Engine, create a collection, test it and then create a second one without the more prolific news organization sites included.
I visited each of my two new search engines, performed a search for the word “love,” added the advanced search operator “more:recent4” to put results in roughly reverse chronological order instead of pagerank, and then I bookmarked that search results page.
So I shared these resources on my personal blog before the conference, then hit the venue with laptop in hand. I attended conference sessions, watched what people were saying about them in the backchannel via my Twitter lists, then found pertinent details about what people were saying, from their organizations themselves, with great efficiency using my custom search engines. It made for some very informative blog posts, quickly put up but with good supplemental details.
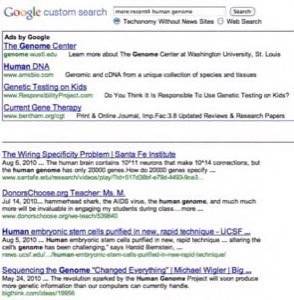
That’s how I did it, and that’s how I’ll do it again in the future. Other tactics I might have employed include subscribing to blogsearch feeds for the conference name through an IM interface so I can keep track of what everyone else is saying in real time, doing the same with Twitter and perhaps another trick or two that I’m just now considering but will test out before talking about. 🙂
Thoughts? Suggestions?
Illustration titled “Blogging Au Plein Air, Jean-Baptiste-Camille Corot” by Flickr user Mike Licht


















{kind=link}