Google announced today that it is closing a number of services that it wasn’t able to attract millions of users to without making any effort. The worst of the lot to lose are two: the Social Graph API and DIY data extraction service Needlebase. Following on the heels of the kitten-stomping-bad sunsetting of Postrank, these latest closures are really meaningful, even if the adoption of the services never was.

Back when there was hope for Needlebase, the Social Graph API and for Postrank, those services represented hope for the web making the world a better place. Of course people can still use stupid Facebook to organize a protest, or Twitter to speak without hinderance to the world, but with the demise of these three efforts, some important things are lost from the web. These are the kinds of things that a benevolent organization would have invested a lot of support in, for the sake of the world.
“As we head into 2012,” Dave Girouard, VP of Product Management at Google and probably the kind of person who boos after children’s Christmas plays, wrote today, “we’ve been sticking to some old resolutions–the need to focus on building amazing products that millions of people love to use every day. That means taking a hard look at products that replicate other features, haven’t achieved the promise we had hoped for or can’t be properly integrated into the overall Google experience.”
Rest in Peace, Needlebase
Needlebase, which came to Google in the acquisition of travel data giant ITA Software, was (is) like a magic wand; you could touch a part of the marbled, veiny web with it – and its magic would flow through every crease and crevice until the web’s swirls and pockets were traced and could be illuminated in a flash of data visualization. Specifically, you could point and click to train Needlebase to recognize the various parts of a web page, then jump from page to page of structured data, extracting information and placing it in a database, map or other visual experience.
If, for example, you were preparing to attend a big conference, you could point Needlebase at the conference speakers’ biographic entries, show it where the home page links are, where the “next page” links are, and then set it free. Like a cross between a bloodhound, a sheep dog and a magic unicorn, Needle would gather all those links up into a bundle. Set them inside a custom search engine and what have you got? Instant access to the collective published knowledge of every speaker’s organization at a conference, usable to better understand what any other speaker says in context. In minutes.
My favorite story about using Needlebase is this one. One day here at ReadWriteWeb we caught wind of a local Salt Lake City newspaper that ran a story about a big new data center opening in town with a mystery anchor tenant. The paper believed that the tenant was Twitter, opening its first data center outside of San Francisco – as the company said it would, in a location undisclosed. We used the (now Google-acquired) web app called Needlebase to investigate.
We grabbed the URL of the Twitter List of the staff of Twitter Inc. and we trained Needlebase’s point-and-click screen scraping tool to recognize what a user name, Tweet text and location field (when there was one) looked like on the page of staff Tweets. Then I clicked a button and said “go!”
In just a few minutes, the most recent 1125 Tweets from staff were pulled into Needlebase and we said “show ’em on a map!” Sure enough, one Twitter network engineer had posted a Tweet with a location attached to it right across the highway from the alleged mystery data center. He’d just left San Francisco, he had Tweeted, and arrived in Salt Lake City ready to get to work.
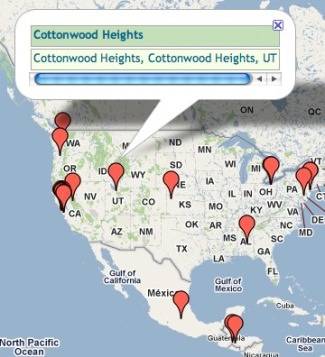
That Tweet was quickly deleted after we reported on it.
Needlebase was one of the most accessible of a class of tools that made data magic available to non developers. Magic.
There is too much information on the web for the human mind to understand it all, of course. The ability to draw sets of it together, to extract and sort it, and thus to discover new qualities about that which is described with the data, is humbling, it is a thing of contemporary existential beauty.
“It’s not simply that there are too many brickfacts [datapoints] and not enough edifice-theories,” writes author David Weinberger in his new book, Too Big to Know. “Rather, the creation of data galaxies has led us to science that sometimes is too rich and complex for reduction into theories. As science has gotten too big to know, we’ve adopted different ideas about what it means to know at all.”
At least some of us have begun to adopt new ideas about what it means to know at all; there are not millions of happy people playing with DIY data extraction tools as a little part of that experience. And since they have not scaled in adoption, Google has decided to dismantle these instruments of ecstasy, just as the curtain began to rise from in front of the stage where the real story of life was to be seen.
The Google Social Graph API was an API that indexed all the rel=”me” links connecting social media profiles around the web. You could use it to search for a person and discover all the places they had profiles. If you cared, that is. Google apparently doesn’t, because now there’s Google Plus. Presumably, not enough other people cared either. I cared though.
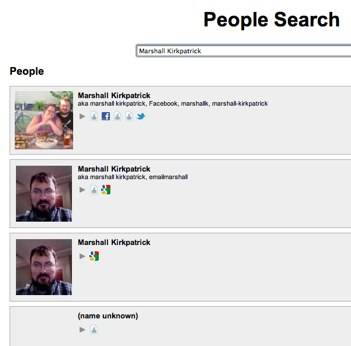
Here at ReadWriteWeb we like to use Martin Atkins’ AJAX interface for the Google Social Graph API to find all the places that people post things around the web, just by searching for their names. It’s a crude use of the tool, so much more could have been done with it.
Right: a search for my name surfaces my blog, Facebook, Twitter, LinkedIn, Quora and other profiles. Who really wants to learn new things about other people though? What a bore!
How else can you programmatically discover, from one hub of a person’s identity, all the arms of their star of activity online? Being unable to know that, or being told to go instead to one single social network to learn more about real dynamic people, feels like a throw-back to the Dark Ages.
PostRank…
The worst loss to humanity at the hands of Google’s startup eating monster of late remains PostRank, which Google acquired this Summer. I can’t bear to write about that again, but the gist of the story is this: Postrank ingested RSS feeds and then let you filter for just the hottest content coming from any source over time; enabling you to subscribe to a much larger number of voices, with the knowledge you’d be less likely to miss anything really important. Google ended that part of the service and made it all about publishers tracking their own social media accolades, though.
The original version of Postrank was like a magic horn that a woodland fairy called Learning and Empathy could hold to its ear to hear the tiniest caterpillar stretch and yawn in the morning, along with the rest of the whole concert of forest noises (blogs), from all around the world. It was captured by Google and refashioned as a mirror for the fairy’s hideous ogre sister Naked Self Interest, which the ogre (a publisher using Google Analytics) thought made her more beautiful and rich with pageviews, but which really only made her uglier and more vacuous every day.
I can’t believe they are killing Needlebase and the Social Graph API. I can believe it, of course, but I’m thankful that my cynicism is still thin enough that it hurts every time something like this happens again. There are only so many more tools like this on the web left to kill, though.

















