We have recently written here about the
ongoing transformation of Web Sites into Web Services. In that post we noted that
with the rise of APIs, scraping technologies and RSS, web sites are really turning into
data services and collectively the web is becoming one gargantuan database. As such, the
web is quickly becoming a platform or foundation that powers new kinds of applications
that remix information in ways not possible before. The web is also becoming much more
connected, not not just on the level of links – but at a much more fundamental, semantic
level.

The big picture is always exciting and important, but the mechanics matter too. How
exactly do we unlock and correlate information from separate web sites? Ideally, we’d
like for all web sites to offer simple and elegant APIs – like Amazon, del.icio.us and
Flickr do today. Alas, this is not feasible today and it isn’t clear that something like
this can be done quickly at all, on a Web scale. So in the meantime, solutions like
Dapper that help you process unstructured
information from HTML, clean it, transform it and re-emit as structured XML – these types
of solutions are worth serious consideration. So in this post we take a close look at all
aspects of Dapper: how it works, what can be done with it, the company’s business model
and legal implications of this service.
How Dapper Works
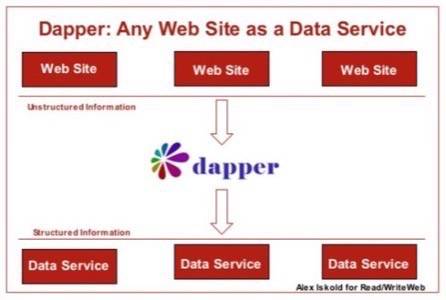
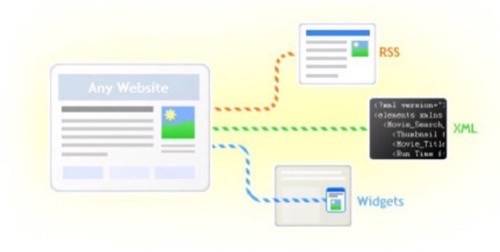
Dapper offers a way of turning any Web Site into a special kind of Web Service – a
Data Service. The difference between a general Web Service and a Data Service is that the
latter offers passive, read-only access to information. The former (general web service)
may also offer ways to manipulate and change the underlying information. Nevertheless,
Data Services are powerful because they unleash information that otherwise would not be
accessible. Here’s an illustration of this in Dapper:
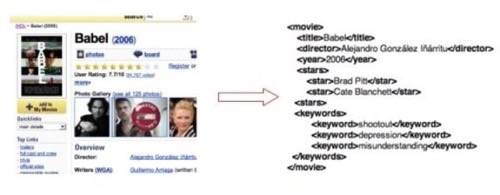
The idea behind Dapper is to create an automatic, visual way of extracting information
from HTML pages. It works by taking a few sample pages as input and then letting users
visually specify the information that should be extracted. Each page is treated like a
record in a database. For example, consider the transformation of a movie page from
IMDB:
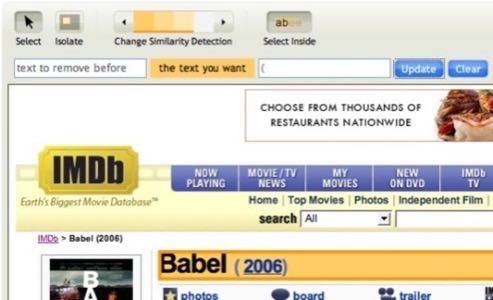
Dapper runs a quick similarity analysis between sample pages. Even though the analysis
is very quick, there is a non-trivial tree-matching algorithm – fine-tuned for HTML –
that powers this aspect of Dapper. After analyzing the pages, Dapper presents the user
with a highlighter tool for selecting attributes of a record. For example, below you can
see how to select a title, highlight a row with title and year, and then chop off pieces
using parenthesis.
Testing out Dapper
The Dapper team has worked hard to make text selection easy, but its interface is
still somewhat confusing. Particularly, the top controls that allow refinement of a
selection needs more work. Right now these controls allow the user to control the
similarity matching algorithm. Since the user only has a vague idea of what this is, this
control is not terribly useful. In any case, presenting this control using a pulldown
with text – instead of a heatmap – would probably be more clear. The other controls are
also unclear; and since there are no instructions, the only way to figure it out is by
trial and error.
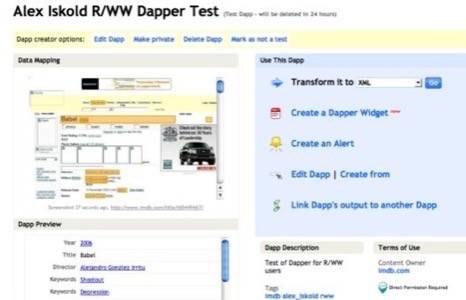
Still, a technical person can use Dapper fairly efficiently. Once you isolate the
information that you want to be captured by a single attribute, you can then name the
attribute and then move onto the next one. When you are done, the next step is to review
and group the content (if you wish). You can then save this application and start using
it in variety of ways.
Dapper Applications
So how can this be used? The first use is straightforward – you can use a “Dapp” to
process a different URL. For example: if instead of Babel, you pass the IMDB link to Departed, you will get back the
information for that movie instead. So this Dapp can be used to turn any IMDB page into a
movie record.
You can also output results into many other formats. Among them you can get results in
RSS, Email and HTML output – which to me do not seem as useful for a single record, but
become much more interesting when you are looking at a set of records. For
example, using the above Dapp and a bit of PHP, you can build an application that
generates a formatted RSS feed of new movies shown on the IMDB home page. In addition to
the movie title, the feed would include information about release year, director, stars
and keywords.
You can also imagine applications that combine different Dapps together. For example,
movie information from IMDB can be combined with movie information from Netflix to
deliver extended information of a film. Going back to our discussion of the Web as a
Database, this is essentially like doing a join between two tables.
The problem that these applications will face is identity. How can you know
that two movies – one at IMDB.com and another one at Netflix – are actually the same
movie? There are various ways of determining this, but all boil down to establishing an
identifier for a movie that is different from the URL. For example, the combination of a
title and director would be a good candidate for such a unique identifier.
So in a nutshell, once the information is extracted, it can be remixed and presented
in many new ways. Freed from HTML presentation, raw information from a web page is
basically the same database record. And we know how powerful relational databases are –
for the past twenty years they have been the backbone of enterprise IT.
Business and Legal questions
Clearly what Dapper is powering is interesting and useful technically. But the
business and legal questions are pressing. Is this monetizable? And more importantly: is
this even legal? Content scraping is a shady area. Some people claim that it is flat-out
illegal. Others say that it is fine, because the content is out there anyway. My take is
that it all depends on how the content is used. If the content is scraped and then reused
without attribution to the original content provider, that is a straight copyright
violation. If on the other hand, the attribution is preserved and the content is remixed
in creative ways that still drive traffic to the original source – then it is probably
fine. In any case, this is an area without much legal infrastructure – so all players
need to be careful.
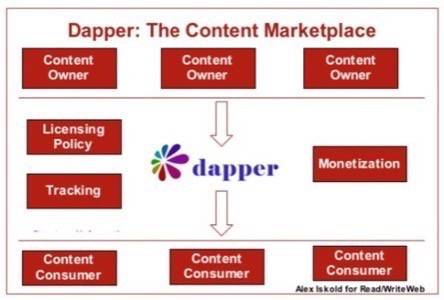
Now Dapper’s approach to the problem is entirely different – the company is attempting
to both monetize and legalize scraping by acting as a marketplace that connects content
owners with companies that want to remix the content. This is both ambitious and a clever
play that might just work. The owners of the content often do not have the technical
resources and business channels to sell their content. They are not against it in
principle, they just do not have the means to do it. On the other hand, the companies
that want to leverage existing content are weary of scraping – it just seems like the
wrong way of doing it. No one would question calling an Amazon API, but parsing the data
out of HTML just does not sound clean.
So Dapper’s answer seems to be spot on – connect the content owners with content
consumers. In the process, establish rules for content distribution, track how it’s used
and help content owners monetize the content. And yes, of course – as with any good pipe
– take a cut in each transaction. So while technical purists would argue that the whole
notion of scraping is a hack, business people and pragmatists would recognize that
Dapper’s approach to the problem has all the ingredients – that might just make it a
successful solution to a real problem.
Conclusion
Will Dapper succeed? It is not obvious and perhaps too early to say. There are a few
things that are playing against it. Firstly, ease of use – which the company is rapidly
solving. This is something that they control directly and should be able to fix. The
second problem is competition. Yahoo! Pipes, Teqlo and Kapow are close enough to be a
threat and to cause confusion in the market. But beyond that, is what Dapper is trying to
do a good idea? It seems to me that the answer is resounding yes.
Clearly Dapper is not an ideal scenario for exposing the world’s information. But it
is a top-down, unintrusive and perhaps the fastest way of turning any web site into a
data service. As such, its power and potential exceeds its drawbacks. We will see what
happens and in the mean time, let us know what you think about the technical, business
and legal aspects of this fascinating company.

















