Content creation at Wikipedia is slowing down. The already small number of active regular editors is on the decline and Jimmy Wales has called for live edits to be held for approval on many pages, a step sure to slow contributions even further.

The tapering of fresh content doesn’t have to mean Wikipedia’s death, though. The site contains a gargantuan amount of human created and tended but largely machine readable and structured data. That’s a potential gold mine in terms of a potential pay-off in innovation. Wikipedia can offer developers opportunities to glean analysis, supplemental content and structured data from its years-old store of collaboratively generated information. All of that is possible, but Wikipedia as a platform can’t be taken for granted.
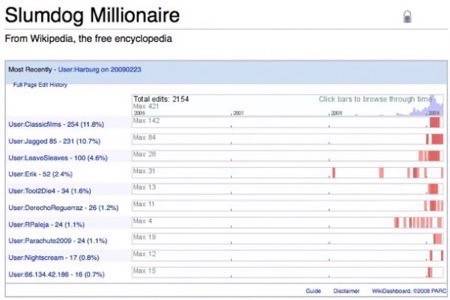
Above: Edit history via the WikiDashboard browser add-on, by Paul Irish.
If the sun is setting on Wikipedia’s time as a fast-growing collection of user-contributed knowledge, maybe that part of the site’s life was just its adolescence. Wiki inventor Ward Cunningham told us he thinks the moves by Wales to require approval before displaying edits are an “inevitable” maturing of the site, though not one he’s necessarily happy about or believes is consistent with The Wiki Way. Nonetheless, the huge mass of knowledge amassed by the world’s biggest wiki now offers developers and other websites all kinds of value that has only begun to be explored.
There is no formal Wikipedia Application Programming Interface (API) but the data there is relatively accesible anyway. It can be downloaded and proccessed locally. This spring a project called WikiXMLDB began offering a thoroughly XML-ified database of Wikipedia as well. We shouldn’t fail to point out DBPedia, as well, where people are collaborating to make structured data available from Wikipedia. People are accessing the data in a variety of ways and are beginning to find good uses for it. One or more formal APIs from Wikipedia, though, would be exciting in ways similar to how it’s exciting that the New York Times is opening up a number of APIs.
What Would People Do With Wikipedia Data?
Wikipedia as a tool to identify key sources of knowledge. Mainstream media coverage of Wikipedia in its early days often focused on the seemingly random contributors to the site. Some old guy with a beard down to his knees and living in a trailer park in New Mexico likes to edit entries about astronomy and the culinary arts. Isn’t that quirky?
Wikipedia has managed to set free in a big way the knowledge stashed away in the minds of people all over the world. Identifying those people in a systematic way is just one example of the kind of value add that can be built on top of Wikipedia. Identifying key influencers online is a fast emerging industry and Wikipedia is one more place that can happen.
The Palo Alto Research Center recently built an application called WikiDashboard, a service to analyze recent changes and editors of any Wikipedia entry. Paul Irish, who incidentally is the editor of one of the best music blogs on the web, turned that data into a Greasemonkey script that gives one click access to the data from any page on Wikipedia (image above).
That’s just the beginning of what could be done with contributor data, though there are so few active participants on Wikipedia that the user data may be more limited than you’d think.
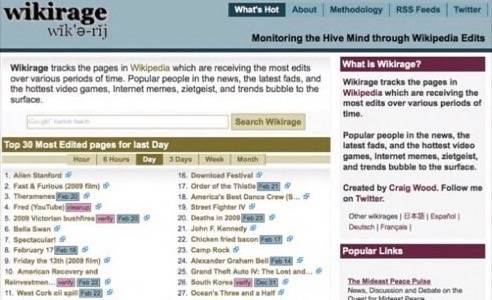
Wikipedia as news radar. Wikipedia puts a great emphasis on current events, but the opposite is true as well – current events are reflected in Wikipedia. The site WikiRage treats Wikipedia edits like signals of significance – its subtitle is “Monitoring the Hive Mind Through Wikipedia Edits.”
We’ve written here about non-advertising-based forms of data mining that could be huge in the future and how big a Facebook sentiment engine could be. Wikipedia edits number much, much lower than Twitter and Facebook updates, but they may be of higher value, and at the very least they seem like an important complement to a social media data mining strategy.
The Best Use Case: Leveraging Wikipedia’s Structured Data
Last month we wrote here that Google appears to be exposing some semantically structured data in some of its search results. Some of that data may be originally analyzed at Google, but a lot of it is clearly coming in from Wikipedia. That’s structured data that many, many companies could take advantage of.
Recommendation service MSpoke has been doing just that. (Disclosure: MSpoke’s Sean Ammirati is the long-time producer of our podcast ReadWriteTalk.)
This business news tracking service uses Wikipedia to train its recommendation engines. Ammirati says that Wikipedia’s disambiguation pages are very helpful in helping the company’s technology know that there are, for example, two famous Michael Jordans – one of whom is a basketball player and the other is a statistician. That kind of distinction makes all the difference when you’re in the business of recommendations.
By using a subset of Wikipedia’s hierarchy of terms, MSpoke has been able to get an immediate foundation for its own taxonomy and quickly understand the content of articles it finds around the web.
This is the kind of thing that Metaweb and Powerset have tried to do in the past, as well. Powerset was absorbed by the Borg, and we’re hearing rumors that things aren’t going well at Metaweb. It’s one thing to build added value from Wikipedia, it may be another to make it what you bet the farm on.
There could be something here, though. Wikipedia could do quite well for itself becoming less a destination site focused on public editing and more an open database, built up and still maintained after years of formerly frenetic public editing.
There’s a chance that Wikipedia still isn’t populated enough to be able to make that leap, that its political turbulence and waning enthusiasm are coming too soon. Only time will tell, but we have high hopes.

















