The innovative OPML browser plug-in BlogRovr is announcing tonight that it has been acquired by PR monitoring and ad sales startup BuzzLogic. It’s a victory for all the startups who face hostile questions about “how are you going to monetize that?” and answer by pointing to the potential for data mining. For BlogRovr users, who piled up the feed subscription and traffic data that make up much of Blogrovr’s value, it’s a clarion call to engage with the hard questions about data portability and ownership.

BlogRovr lets you identify what blogs you read, then notifies you when any URL you visit has been linked to by one of those blogs. That technology will remain free but will now be put to use for PR monitoring and advertising sales by BuzzLogic.
Both of these are companies we’ve covered a lot here because they are very interesting. BuzzLogic is interesting because they use sophisticated algorithms to determine blogger influence that are practically unfeasible for most users to replicate through free, public methods. BlogRovr is interesting because, amongst other things, it is a fascinating way to leverage RSS and OPML data. See for example our interview with BuzzLogic co-founder Mitch Ratcliffe in 2006 and our initial review of BlogRovr in 2007.
Before you sell my data, even in anonymized aggregate, to a PR and ad sales firm – should I be able to export my clickstream and the subsequent analysis? Is that my data? Is it BlogRovr’s to sell without concern for my access to it? This announcement brings up a number of interesting questions about Data Portability.
Below, a screenshot from BuzzLogic’s dashboard.
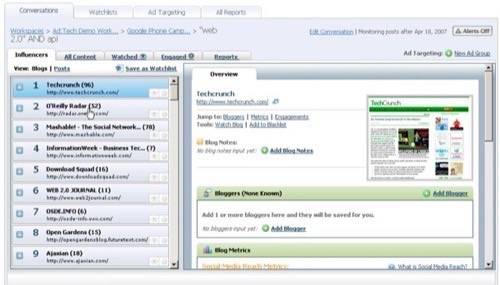
If I Use Your Tool and You Use My Data – Who’s Property is the End Product?
Presumably Blogrovr is or is going to track user clickstreams (browsing history). That, combined with the overlap with subscribed blogs, will be useful in determining blogger influence and a price point for rapid ad placement.
This certainly isn’t the entirety of what BuzzLogic has acquired – BlogRovr execs are being given extensive responsibility over BuzzLogic technolgies as a whole. The minds behind the browser plug-in may be as valuable as the data it churns out, but the data is important to discuss.
On one hand, the company used its proprietary technology to capture this data in a way that users are practically incapable of capturing themselves – at least the overlap with all subscribed blogs. On the other hand, BlogRovr minus their 180k users isn’t good for much of anything.
I asked Chris Saad, Chairman of the Data Portability Working Group, what his take on this question was. “If the data was generated for or by your behavior then you co-created it,” he said, “therefore u should have co-ownership of it at least.” What does that mean, practically? As a thought exercise, should BlogRovr split its acquisition price somehow with it’s users? “No,” Saad said, “BlogRovr gets to keep the money and the aggregate derived data – but the user should be able to export their own data as well, and perhaps even request their account to be deleted.”
That sounds reasonable to me, but that’s not what’s being made available. Users are allowed to export their OPML file of subscribed feeds – but all other data is unavailable.
Is Clickstream Data a User’s Own Responsibility?
Pundit Steve Gillmor has been arguing lately on the Gillmor Gang (now hosted by TechCrunch – thanks Mike!) that data portability advocates are wrong to demand that services capturing their clickstream data turn that data over to users. He, and if he’s alone he’s probably all the more right, argues that user clickstream data is a user’s responsibility to capture if it’s so darned important. We don’t need anyone to give it to us – we already have access to it.
While that may be technically true of browsing history, it is much less true of the subsequent analysis of history cross referenced with blog subscriptions. In theory though, is that data more difficult to access for a typical user than the clickstream is? Neither is particularly accessible without some technology, but if a company builds that technology do they then own its fruit?
Saad again says, “if BlogRovr is capturing it, then they should share it. It’s user generated content.” I’m not sure it’s quite that simple, but it might be.
It seems to me that there aren’t clear answers around any of this. Some people and companies are engaging with these questions, but BlogRovr’s Marc A. Meyer admits that his company simply hasn’t been one of them. That’s a refreshingly honest answer, and better than I got from Meyer’s new PR/ad network bosses – but so what? The company was clearly blazing a trail in terms of using users’ data – do they not have a responsibility to explore the other half of the equation – user access to that data?
Maybe This Isn’t About User Rights
It’s also possible that Data Portability is best advocated not from a position of right and wrong, of user rights, but instead as a matter of competitive advantage. If BlogRovr had a viable competitor that differentiated itself by offering users access to their data throughout the process – perhaps that competitor could emerge victorious. Would a PR/ad network have bought such a company, though, if it offered to hand over this valuable user data? Would enough users have cared to make such differentiation meaningful as a competitive advantage?
There are no end of questions that still need answers in regards to data portability. For now, BlogRovr and BuzzLogic deserve congratulations at least for recognizing the value of user data in the blogosphere. How should the rest of us feel about the news, though?

















