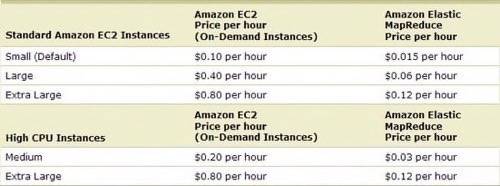
Amazonannounced today that it is bridging two of its web computing services, EC2 and S3, with Hadoop, an open-source project that brings the same distributed data processing power as Google’s MapReduce. In fact, it is calling the new service Amazon Elastic MapReduce. The new service will allow its EC2 customers to perform distributed MapReduce queries on enormous datasets stored in S3, paying only for the computation time they need.

Hadoop has been an open-source project in the making for the last few years, inspired by Google’s white paper on its version of MapReduce. The technology is an almost perfect fit with Amazon’s growing web services, matching distributed CPU time with vast data storage requirements, both things that fit well with the cloud model.
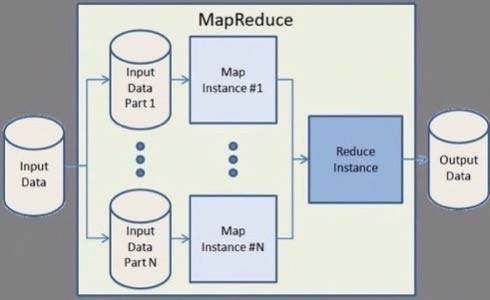
The way MapReduce works is a fairly straightforward concept: You take a problem that requires working with a giant (and we’re talking massive – sometimes petabytes) dataset, distribute working with the dataset over thousands of separate processes (called mapping) and then taking the thousands of results you get back and reducing those results into a single master result. For certain tasks, MapReduce can vastly improve the efficiency of these types of tasks, and adding more computing power gives you a linear improvement in speed.
Yahoo! has been using its own version of Hadoop for a while now. And even before this offering, larger Amazon Cloud Computing customers have already begun to use Hadoop in EC2. This is from Wikipedia‘s article on Hadoop:

As an example The New York Times used 100 Amazon EC2 instances and a Hadoop application to process 4TB of raw image TIFF data (stored in S3) into 1.1 million finished PDFs in the space of 24 hours at a computation cost of about $240 (not including bandwidth).
As Amazon says on its blog, “After a while [developers] tend to report that they begin to think in terms of the new style, and then see more and more applications for it.” Which we believe means that MapReduce is the new, big hammer, and as developers start looking around, every dataset starts looking like a nail. This is good news for Amazon as it only stands to profit.