Aggregate Knowledge, which operates a content discovery network under the brand name Pique, today announced a deal with BusinessWeek to deliver “user-driven content suggestions” on their website. It’s the latest in a string of similar deals – Aggregate Knowledge powers “discovery” of both editorial content and product recommendations for over 100 websites, with a particular focus on retail and media. In this post we take a closer look at the implementation at BusinessWeek – and ask if the results come up to scratch.

At last year’s Supernova, Aggregate Knowledge CEO Paul Martino referred to his company as the “world’s largest implicit social network.” The company told ReadWriteWeb today that media sites like BusinessWeek.com, WashingtonPost.com and LATimes.com are using Aggregate Knowledge’s Pique Discovery Network “to help users discover new and exciting content on their site.” The company has some high powered backing, including uber VC firm Kleiner Perkins.
How Well Does it Work?
Here’s how Aggregate Knowledge describes the system for BusinessWeek.com:
“When a reader clicks on a breaking news story on the site, the Aggregate Knowledge Pique Discovery Window automatically provides user-driven content suggestions in the form of More from BusinessWeek. These suggestions are based on what visitors are actually reading across BusinessWeek.com.”
I clicked some stories on the BusinessWeek.com homepage, and noticed a “More from BusinessWeek” list of links to the right of each story. However, none of these links seemed very relevant to the story. Check out this example from a story about Apple iTunes:
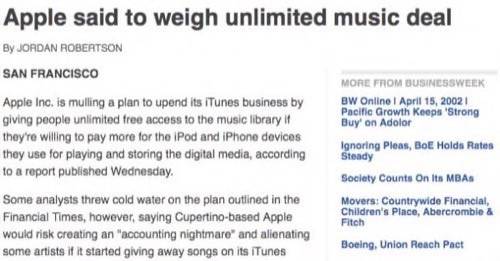
No Apple or even tech stories are linked to. Here’s another example – about Russian police visiting BP offices. Curiously, this one lists an Apple story!
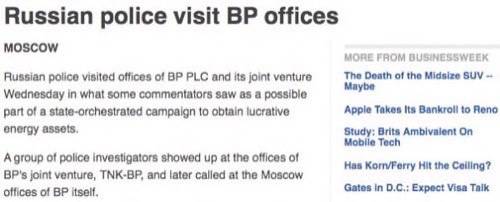
No Actual Content Analysis?
So based on my tests, it doesn’t seem like there is much – if any – semantic analysis of the page content in order to come up with the “More from BusinessWeek” links. Reading between the lines of the AK quote above, this discovery system is based on clicks and not content.
It appears as if this is collaborative filtering – i.e. users who clicked X also clicked Y. This is basically the system that Amazon and Netflix use. For Aggregate Knowledge, collaborative filtering is still going to give interesting results. But how is it better than – for example – the ‘Related Entries’ plugin that we use here on ReadWriteWeb (which is based on tags, and so is much more closely aligned to the content itself). See bottom of this post for an example.
Surely for media sites a content discovery system that analyzes the content of a page, such as Reuters Open Calais does, would give better results. Please let us know your opinion in the comments.

















