Last week, I talked to Google Search lead designer Jon Wiley about the process of designing Google’s iconic interface. What goes on behind that white box? For the second part of my interview series with the people who make Google Search, I talked to Google Fellow Ben Gomes. He’s one of the elite engineers addressing the never-ending array of challenges we users pose by asking ever-more-complicated questions of Google.

The first time I spoke to Ben, he was introducing me to a brand new Google concept called Search, plus Your World. This time, we were able to delve much deeper into the fundamentals of Web search. Computing power at Google’s scale is awesome to behold, and I asked Ben to take us along for a search query’s ride one step at a time.
The Index
ReadWriteWeb: Where does search begin?
Ben Gomes: The journey of a query begins well before the user has typed in the query or even thought about the query. The first step of that journey is crawling and indexing the Web’s content.
We fetch tens to hundreds of billions of pages. When I first got here [in 1999], it was about 50 million pages, and that was the biggest index then. It’s hard to imagine, but it’s three orders of magnitude bigger today. We’re used to this sort of growth in the tech world, I suppose, but three orders of magnitude is still a heck of a lot.
We’re really quickly crawling the content that’s changing fast. The content that doesn’t change as fast, we don’t crawl as often. And then, we’ve gotten really good at bringing that data from the Web to the user in a very short period of time.
When I joined Google, it would take us about a month to crawl and build an index of about 50 million pages. Today, with real-time search, that can happen in some cases in less than a minute.
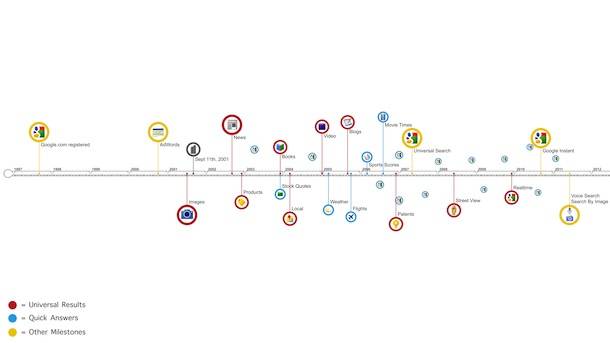
It’s like the index in the back of a book, but because its so large, it’s a lot more complex than that. You can think of it like this: Suppose you had to assemble a whole bunch of widgets from parts, and you have to do this repeatedly in the course of a day. What you would do before that is set those parts up optimally, so that you could assemble those widgets as quickly as possible when the time came.
Building an index is kind of like that. We have to set it up in such a way that it’s very quick for you to actually construct the result page at the moment the user asks for it. So, you type in the query “49ers,” and within a fraction of a second, you get back the search result page that says, “We found 52 million pages that matched, and here’s the top 10, and here’s another thousand.” That’s sort of the brawn of the whole system.
“It’s providing you with that intimate feedback loop that allows you to understand what the Web is saying.”
The Query
RWW: So what’s the brain behind the system?
BG: Ranking is the brain behind the system. What it does is, it looks at over 200 signals to determine which are the most relevant pages to your particular query. So as the user starts typing in the query, what happens? As you start typing, you notice auto-completions. These are predictions of what you might want to type. And with Google Instant, we begin to provide you with actual results right then. This is enabling you to formulate your query on the fly.
So you start typing “owl,” and in your mind “owl” is about the bird. But it turns out “owl” also refers to [the Online Writing Lab] at Purdue, it refers to other things on the Web that people talk about when they use the word “owl.” So you [finish] typing “owl bird,” and then you get what you want.
Google Instant enables you to formulate a better query by letting you see the results even as you’re typing. It’s providing you with that intimate feedback loop that allows you to understand what the Web is saying.
Understanding The Query
RWW: How does Google begin to understand the query?
BG: The query is sent back to Google through the Internet. Typically, this is a journey of over 750 miles in either direction. We have data centers all over the world, but, on average, your query travels about 1,500 miles.
The scale of Google search:
- On average, a Google search query travels 750 miles each way, to and from the data center.
- 16 to 20% of queries that get asked every day have never been asked before.
- Google has answered 450 billion unique queries since 2003.
- Last year, Google made around 500 changes to search.
Behind that, all this work we’ve done setting up the index now comes into play. We parse the query, we understand what your intent was, we [may] personalize the results, and then we send it off to our giant index and get back the top results for your query.
In addition to the results themselves, we need to create the presentation of those results, the titles and what we call the “snippets,” the two lines of text that you see. In order to do this, we look at the copy of the Web that we keep and find the most relevant parts of every page, bring up those two most relevant lines for your query and show those to you for each result.
This is also an enormous amount of computation. It’s going from the few words that you typed in to the result pages that we found, to find where on those pages is the text most relevant to your query.
In the case of Instant, we’re doing that as you’re typing, so the whole process is compounded. So this complex process of ranking is happening in the middle of your typing. If we did this naïvely, we’d be ranking almost 20 sets of results for every query you type, but we are more sophisticated about it. We do a lot of caching and so on.
Then, at the end of that, you get back this beautifully presented result page.
Overall, we put a huge amount of effort into speeding up the connection between your brain and that information you’re seeking.
Personalization
RWW: How do searches get personalized for the user?
It actually happens at every stage of the pipeline. When you start typing your query, if you’re signed in, the auto-completions will prefer queries that you’ve typed in before. If you’re in a given metro area, we will prefer queries that make sense to you in that metro area.
The second level it happens at is, when we process your query, we also take into account your Web history and so on in order to guess at your intent. During ranking, the process of actually looking at the documents, we also take into account personal signals that make sense for you, and when we search for your personal content in Search, plus Your World, we take into account your personal signals over there.
Finally, when we have the full set of results assembled, we then customize them for you.
So personalization of your results is deeply embedded right through the search process. Some of that is giving you the right context for things like date and place, and some of it is personalization based on your previous queries and so on.
Changing Search
RWW: Obviously, Google has to change over time. How do you change a system this complex?
BG: Search is a really complex system, so when we make changes to it, we go through a rigorous process of testing it. We do what are called precision evaluations, where we make some change with ranking, and then ask human raters to evaluate whether it’s a good change or not. We do something like 50,000 of those a year. Some of these things will turn into live experiments. We do something like 10,000 side-by-sides, where we look at the full set of results for algorithm A, algorithm B, which is better, and we ask human beings to [determine] that.
“If you look at search like a big jumbo jet, this is like changing the engines in flight.”
For more feature-oriented experiments where we’re changing the interface in some ways, we do another 10,000 or so live user tests a year. Out of this, we launch about 500 changes to search a year, more than a change a day. So if you look at search like a complicated machine, like a giant jumbo jet – although it’s probably, in some ways, more complex than that – this is sort of like changing the engines in flight before you land.
The Changing Web
RWW: The nature of the Web is changing. It’s more dynamic and application-focused and less like a bunch of pages. How is Google adjusting to that change?
BG: There’s a large class of information that remains as content on the Web. It may be embedded in a Flash application in some cases and so on, and we work very hard to extract information from Flash pages and PDFs and things like that. Some things are actually full-fledged applications, and it doesn’t make sense to be indexing them in the traditional sense.
For instance, it doesn’t make sense to index the random pages that we may find about flights. They’re out of date. They’re not particularly relevant. In those cases, we’re going and understanding the data more fundamentally. We can get the equivalent data as feeds from those sites, and then we can index that data side by side.
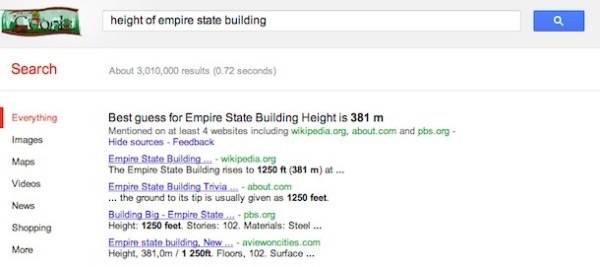
In a few cases where we actually know the particular kind of knowledge that you want, for instance, you want the height of the Empire State Building, we will synthesize a response out of the results and show you the actual height. That’s a direction we’re moving to further in the future.
We’ve gone from data on the Web, to just presenting information, to actual knowledge that answers the question you are asking.
The guiding principle here is getting the user to the information they want as quickly as possible. We are providing an easy way for the user to get to those sorts of quick facts.
But by and large, the data that people are looking for in terms of their search needs is still available as text from the Web, today at least.
Future Challenges
RWW: What are the hardest problems for search right now?
BG: As we begin to answer a certain kind of query, people ask more of them. 16% to 20% of queries that get asked every day have never been asked before. We estimate that there have been about 450 billion unique queries asked of Google since 2003. It’s a pretty staggering number.
What makes it really challenging are the things you’ve never seen before, and yet you have to be prepared to answer. And as we get good at answering those things, people will ask us yet new things that we’ve never seen before.
Queries get longer and more complex, and a lot of the ranking changes are handling that length and complexity. That progress happens relatively silently, right? A query that didn’t work yesterday worked today, and a more complex query tomorrow won’t work, and it will work the day after. So that’s the nature of the progress.
We’re also going down the path of understanding entities with things like Freebase [an open structured database of semantic information acquired by Google in 2010]. Understanding the relationships between things.
We’re beginning to answer simple questions today, like the height of the Empire State Building, but we want a lot more in that realm, to understand a lot more about things in the world and how those things are related to each other, and then answer questions about those things based on your query. That’s the part we’re just barely scratching the surface of now, and we hope to see a huge amount of progress in the future.
“The guiding principle here is getting the user to the information they want as quickly as possible.”
A primary goal of ours is to understand language. There’s a lot of subtlety in that. Even between the singular and the plural of a word, there’s a huge amount of complexity. “U.S. president” tends to refer to the current president. “U.S. presidents” tends to refer to the list of all of them. People have subtle differences in meaning when they change words even by small amounts.
One of the key areas where we’ve made huge progress in the last few years is synonyms. We started working on this 10 years ago, and it was a really hard problem. “Car” and “auto” often refer to the same thing, but not always and not in all contexts. “Auto” sometimes means “automatic.”
We’re trying to understand that complexity in order to understand your intent, and then answer it by understanding the documents and their information intent, and matching the two.
Want to hear more from Ben Gomes? Check out this 6-minute video about the evolution of search:

















