


Latest News

The five best AI apps for students in 2024
Artificial intelligence in education is becoming increasingly common. So much so, that tech giants like Meta have already rolled out virtual reality headsets in some classrooms across the world. Consequently, there are already a multitude of AI apps geared towards students, helping them sail through their studies. According to a Tyton Partners report, nearly half…

















Artificial Intelligence

The five best AI apps for students in 2024
Suswati BasuTech journalist
Anthropic’s Claude AI is coming to iOS as an app
Ali ReesTech journalist
Cryptocurrency

Ex-FTX Europe chief pays record $1.5M for Titanic gold watch
The former head of FTX Europe has paid the highest sum ever for a piece of Titanic memorabilia. Patrick Gruhn reportedly paid $1.5 million for a gold pocket watch recovered from the ship’s richest passenger, The Wall Street Journal stated....
Suswati BasuTech journalist



Entertainment
The five best AI apps for students in 2024
Suswati BasuTech journalist


New Mario and Sonic Lego sets arriving are this summer
Ali ReesTech journalist
Technology
Starfield’s latest patch adds much needed quality of life improvements
Continuing its trend of making continual improvements to Starfield post-release, Bethesda has released a huge new update for the spacefaring RPG that includes many much-needed quality-of-life fixes fans have been clamoring for. According to the Steam patch notes, this Starfield...
Ali ReesTech journalist


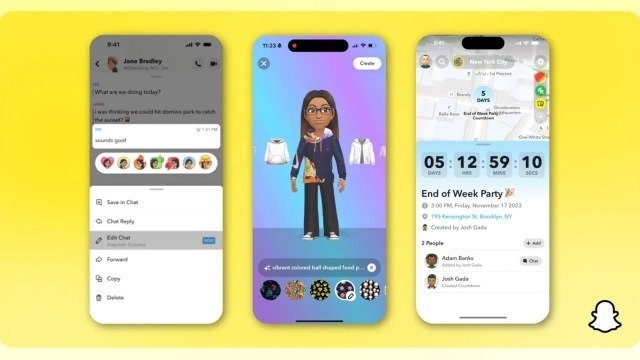
New Snapchat update finally introduces editable Snaps
Ali ReesTech journalist

These 4 games are coming to PlayStation Plus in May 2024
Ali ReesTech journalist
AR / VR

Smartphones


We are an award-winning tech website where trusted research and expert knowledge come together
Since 2003, we have helped millions of people learn how to solve tech problems large and small. We work with credentialed experts, a team of trained researchers, and a devoted community to create the most reliable, comprehensive and delightful content on the Internet.
1M
Monthly Readers1.4M
Followers on X35K
ArticlesTrusted
for 20 years5000+
research hrs100+
EXPERT CONTRIBUTORSPopular Topics
Get the biggest tech headlines of the day delivered to your inbox
Explore the latest in tech with our Tech News. We cut through the noise for concise, relevant updates, keeping you informed about the rapidly evolving tech landscape with curated content that separates signal from noise.
Explore tech impact in In-Depth Stories. Narrative data journalism offers comprehensive analyses, revealing stories behind data. Understand industry trends for a deeper perspective on tech's intricate relationships with society.
Empower decisions with Expert Reviews, merging industry expertise and insightful analysis. Delve into tech intricacies, get the best deals, and stay ahead with our trustworthy guide to navigating the ever-changing tech market.