Probase is a Microsoft Research project described as an “ongoing project that focuses on knowledge acquisition and knowledge serving.” Its primary goal is to “enable machines to understand human behavior and human communication.” It can be compared to Cyc, DBpedia or Freebase in that it is attempting to compile a massive collection of structured data that can be used to power artificial intelligence applications.

It’s powered by a new graph database called Trinity, which is also a Microsoft Research project. Trinity was spotted today by MyNoSQL blogger Alex Popescu, and that led us to Probase. Neither project seems to be available to the public yet.
These and other projects shed some light on Microsoft’s search and big data ambitions.
Probase
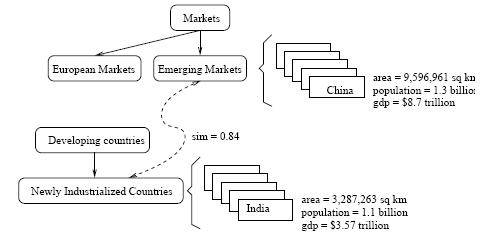
The project site claims that Probase is richer than other ontology/taxonomy knowledge bases like the ones mentioned above because it structures data according to three dimensions: concept, data and relationship dimension. Its concept dimension contains about 2.7 million concepts. According to the Probase site, Freebase contains 1,450 concepts, DBPedia contains 259 and ResearchCyc contains approximately 120,000.
One of the most important elements of Probase is that it doesn’t regard the data it contains as facts. “Data in Probase, as knowledge in our mind, is not black or white,” the site says. “Probase quantifies the uncertainty.” Here’s a more expanded explanation:
Probase has a large data space. As an example, Cyc contains about two dozen painters, while Probase has close to 1,000 of them ordered by their popularity. The importance of data scale becomes more apparent for less frequently used concepts, or concepts on the long tail. Take the concept Chinese provinces as an example, Cyc does not contain a complete list of Chinese provinces, while Probase has all the provinces (ranked by popularity). The reason that Probase is able to accumulate a large amount of data is because of its probabilistic nature. We do not regard the data in Probase as facts, instead, we regard them as claims or beliefs associated with probabilities modeling their plausibility, ambiguity, and other characteristics. Furthermore, we regard external data, such as the Web, Freebase, DBPedia, dictionaries and encyclopedias, IMDB, Amazon, etc., as evidences that can add to or modify the claims and beliefs in Probase. This means Probase is able to integrate information of varied quality from heterogeneous data sources.
For more background on the problems posed by this sort of project, research the history of Cyc.
This would be very useful in Microsoft Bing, which was originally billed as a more semantically intelligent search engine. In 2008 Microsoft acquired Powerset, a semantic search engine that searched Freebase and Wikipedia for answers. According to former Powerset engineers on Quora, the technology may have been used in Bing Reference.
Google acquired Metaweb, the company that developed Freebase, last year.
Trinity
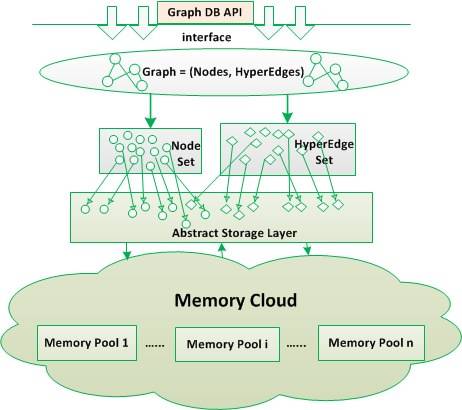
According to the site, the main features of Trinity are:
- Data model: hypergraph.
- Distributed: Trinity can be deployed on one machine or hundreds of machines.
- A graph database: Trinity is a memory-based graph store with rich database features, including highly concurrent online query processing, ACI transaction support, etc. Currently, Trinity provides C# APIs to the user for graph processing.
- A parallel graph processing system: Trinity supports large scale, offline batch processing. Both Synchronous and Asynchronous batch computation is supported.
Here’s an illustration of its architecture:
Microsoft’s other NoSQL related projects include Windows Azure Table Storage, a big table-based database for the Azure platform, and Dryad, an alternative to Hadoop.
Other examples of graph databases include Neo4j, HyperGraphDB, InfiniteGraph and FlockDB.
The Future
It’s not hard to connect the dots between Bing, Dryad, Probase and Trinity. Microsoft is building a set of tools to rival those used internally at Google and the open source tools used by companies like Facebook and Twitter. The interesting thing will be what Microsoft does with its data.
RedMonk analyst and co-founder Stephen O’Grady looked at the value of software in a recent blog post. O’Grady looked at the changing role software over three generations, using Microsoft, Google and Facebook as the primary examples.
For Microsoft, software has always been the product. Google turned this around, by using proprietary software and custom infrastructure to power a service. Facebook takes this a step further – it uses commodity open source software. It uses PHP and MySQL and gives away custom in house software like Cassandra and Hip Hop. Its strategic advantage is in its data.
Although Microsoft probably won’t give away Dryad or Trinity, it looks like it might be moving towards the Facebook model. Will Microsoft be able to turn itself around and become a data company instead of a software company?
Lead image by nasa1fan/MSFC

















