“What is Hadoop?” is a simple question with a not-so-simple answer. Using it successfully is even more complex.
Even its creator Doug Cutting offered an accurate-but-unsatisfying “it depends” response when I asked him last week at the Strata+Hadoop World conference to define Hadoop. He wasn’t being coy. Despite serving as the poster child for Big Data, Hadoop has grown into a complicated ecosystem of complementary and sometimes competitive projects.

Which is precisely what makes it so interesting and powerful.
As Cutting went on to tell me, Hadoop can fill a myriad of different roles within an enterprise. The trick to getting real value from it, however, is to start with just one.
The New Linux
Hadoop, avers Cutting, is much like Linux. “Linux, properly speaking, is the kernel and nothing more,” he notes, channeling his inner Richard Stallman. “But more generally, it’s an ecosystem of projects. Hadoop is like that.”
But this wasn’t always the case.
Hadoop started as a new way to process (MapReduce) and store (Hadoop Distributed File System, or HDFS) data. Ten years later, Hadoop has become motley assembly of oddly-named projects, including Pig, Hive, YARN, Hbase, and more.
Already a far-ranging ecosystem, Hadoop is the largest galaxy in an ever-growing universe of Big Data (though people often use Hadoop to mean Big Data). Ultimately, says Cutting, Hadoop expresses a certain “style” of thinking about data, one that centers on scalability (commodity hardware, open source, distributed reliability) and agility (no need to transform data to a common schema on load but rather load it and then improvise on schema as you go along).
All of which, he says, means one simple thing: “More power to more people more easily with more data.”
Calling Your Hadoop Baby Ugly
“Easily,” however, is in the eye of the data science beholder.
Hadoop, despite its power, has yet to see mainstream adoption (it still accounts for just 3% of the enterprise storage footprint, as 451 Research finds), largely because of how complicated it is. And that’s not helped by how fast the Hadoop ecosystem continues to grow.
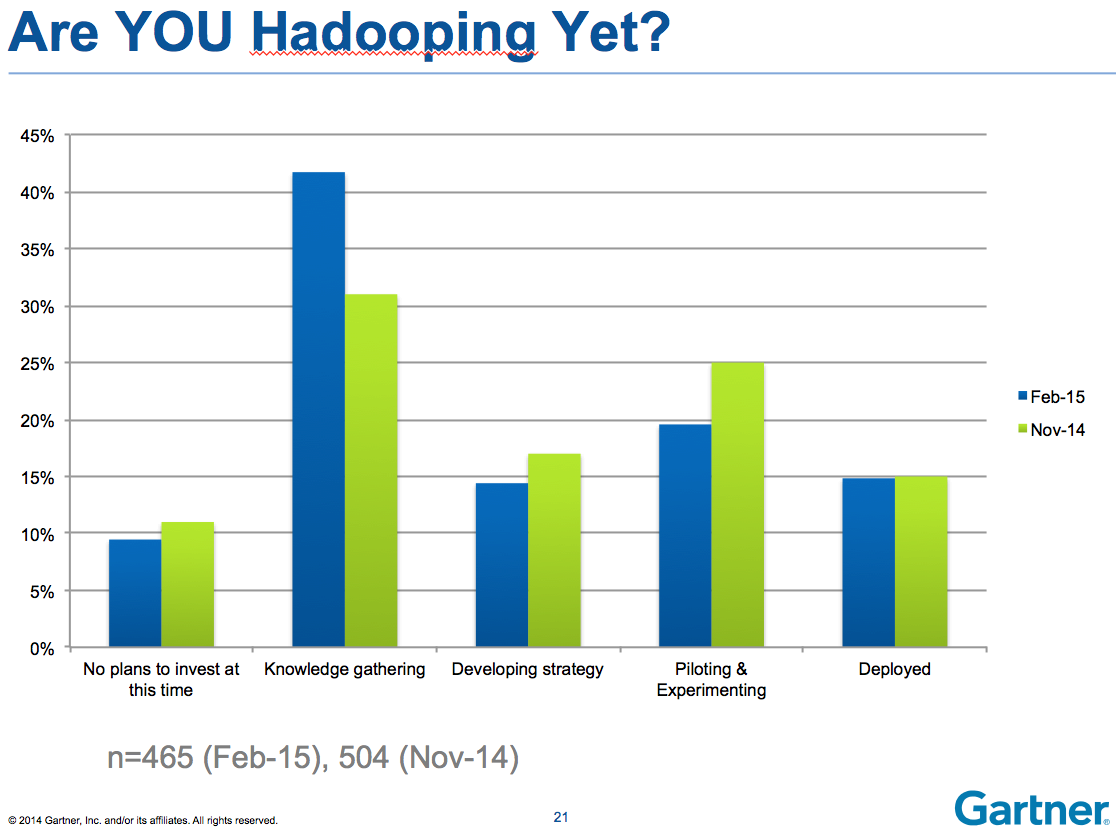
This, in turn, may be one reason that Hadoop deployments haven’t grown as fast as they otherwise might, as Gartner analyst Merv Adrian highlights:
Cutting recognizes Hadoop’s warts. While it would be too much to say he celebrates them, it is true that he’s not embarrassed by them. At all. As he puts it, “One of the things I liked when I got started in open source is that I didn’t have to apologize. Nor did I have to deceive and say a project could do things well if it actually couldn’t.”
The code, after all, tells its own truth.
Hence, he’s comfortable saying things like:
Hadoop is what it is. It used to be a lot worse and used a lot less. It’s gotten a lot better and is now used a lot more.
How much more? Despite the Gartner analysis above, Cutting told me that Cloudera sees the Hadoop world doubling each year: “doubling of number of customers, company revenue, customer cluster sizes, and even Strata has roughly doubled each year.”
That’s good, but what would make it move even faster? Otherwise stated, what does he see as the biggest barriers to Hadoop adoption?
Barriers To Hadoop World Domination
There are a few things that block Hadoop’s progress, Cutting tells me. First, there are features that enterprises need that Hadoop and its ecosystem still lack.
More than this, he suggests, there are missing integrations between the different stars in the Big Data/Hadoop galaxy. In other words, it’s still not easy or seamless to move data between different tools, like Hive to Solr or MongoDB to Impala. Enterprises want to use different tools to deal with the same data set.
We’re also still waiting on applications to remove complexity and streamline Hadoop. As he suggests, Cloudera sees common use cases—like risk management for financial services companies—that require the same tools to solve the problem. At some point these “recipes” for success (use tools X and Y in this or that way) need to become productized applications, rather than each enterprise assembling the recipe on their own.
Finally, Hadoop needs more people trained to understand it. If Strata roughly doubles in size each year, that implies that half are newbies. Getting those newbies up-to-speed is paramount to helping their enterprises embrace Hadoop.
Start Small To Go Big
There are, of course, a swelling number of online and classroom-led courses to teach people Hadoop, which is one way to become proficient.
But Cutting thinks there’s another way to drive fast, effective learning. As he puts it, “What works best and leads to the least disappointment is to look at your business and find the low-hanging fruit, a discrete project that could save or make the company a lot of money.”
Though Cloudera sells a vision of enterprise data hubs, he thinks that’s more of an end goal, not the first step. “Don’t try to jump to moving your company to an enterprise data hub,” he declares. “Not at first. Start with a point solution with relatively low risk.” Then grow the solution (and the team’s understanding) from there.
“If you’re doing it right,” he continues, “others will find out what you’re doing and they’ll ask to add extra data to your Hadoop setup. Maybe it doesn’t solve your immediate business problem, but it allows Hadoop experience to grow organically within an organization.”
Which seems like the exact right way to go big with Big Data: by starting small.
The reality, as he notes, is that enterprises don’t turn over their technology investments very fast. As such, Hadoop primarily gets used for new applications, with the majority of enterprises still running themselves on old technology. It will take years for Hadoop to take its rightful place in the enterprise, but by starting small, Hadoop-savvy employees can position their companies to profit all along that growth trajectory.
Image courtesy of Shutterstock