Yesterday, Tristan Louis, my friend and colleague (and I reserve that phrase specifically for friends and colleagues, that’s not a euphemism) published on his TNL.net blog the results of his own study. Louis – a professional technologist who founded Internet.com and who personally contributed to the RSS specification – looked into the relative states of compliance by the world’s most trafficked Web sites with the published standards of those sites’ corresponding document types. Fourteen of Alexa’s top 25 sites list HTML5 as their doctypes, he noted. Running their home pages through the W3C’s Validator, he learned most of them have significant compliance errors, including Amazon.com with 516 errors, and YouTube with 120.

Not one to cast stones lest we be stoned, I ran ReadWriteWeb.com’s front page through the Validator. It reported 277 errors and 83 warnings with respect to our own compliance with our stated XHTML 1.0 Strict document type. But what exactly does that mean? Are we truly producing Web pages that browsers can’t parse? What is it, specifically, that we’ve violated, and do we owe any fines?
An examination of the verbose listing from the W3C Validator report on our front page reveals an interesting fact about what constitutes “non-compliance:” Most of the “errors” listed were generated by embed code – the instructions that enable readers to Like our pages on Facebook and share pages with LinkedIn and Twitter users, and enable us to keep track of usage statistics for our advertisers.
It’s code whose architecture and syntax we don’t control, and it’s the basic code that other Web sites around the world rely upon to perform exactly the same functions for them. But it makes us violators, lumping us into the same group that Louis chastised for their “disregard for standard compliance.”
Isn’t Louis concerned that W3C treats as “erroneous” or “non-compliant” any code whatsoever that it’s not responsible for specifying itself, including the embed code elements of the social networks upon which the business of the Web depends?
“Embeds are indeed a valid concern, but I suspect it ties to something deeper, which is a general attitude in our industry that ‘invalid code will happen,'” Louis tells RWW. “If most sites were valid without the embeds, the owners of those sites would then put pressures on external providers to shape up and provide code that embeds cleanly (it is possible for that to happen).”
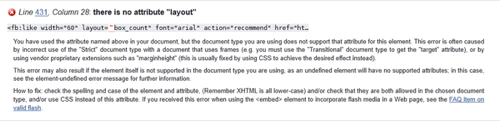
In places where we’ve embedded Facebook code on our home page, the Validator considers instructions that include the namespace declarer fb: to be erroneous. What’s more, every part of those instructions generates a single error, so the entire instruction line may be deemed guilty of ten separate counts or more of infraction. The screenshot above shows one example of an attribute (among many in the same line) that the Validator claims doesn’t exist, because the fb: namespace declaration doesn’t exist in the specification. So when Facebook doesn’t comply, we’re guilty by association.
Although as Louis describes it, we may be able to get off on a technicality.
“The issue with Facebook prefacing its embed with fb: has to do with them opening up a separate namespace for their code, which is the correct way to do this in XHTML. However, HTML5 does not seem to allow for namespaces, which apparently makes it impossible to mix HTML5 with other namespaces,” notes Louis. “This was an arbitrary decision that leaves many third party developers with no way to extend HTML.”
The concept of implementing extended namespaces in HTML5 has been deliberated by W3C participants for well over five years, with the resolution being no real resolution at all. Extended namespaces is one of the hallmarks of XHTML, the first XML-based implementation of HTML, whose development dates back to 1998. One of the problems with formally enabling extended namespaces in HTML5, many developers say, is that it ends up changing the Document Object Model (DOM) – the construction of the Web page – and browsers may find they have to resort to unique means to handle those changes. Or to put it metaphorically, there’s no telling what ripples in the pond extended namespaces could create, because every browser has a different pond.
For XHTML, the HTML namespace is one of its extensions. Thus you can declare the HTML namespace using <html xmlns="http://www.w3.org/1999/xhtml">. But as the WHAT Working Group Wiki explains, “HTML is being defined in terms of the DOM and during parsing of a text/html all HTML elements will be automatically put in the HTML namespace, http://www.w3.org/1999/xhtml.” So HTML is there to establish the DOM, and nothing more.
The WHATWG was formed as an effort to get HTML5 moving again, not really contrary to W3C but, to some extent, in defiance nonetheless. As it’s been explained to me, W3C is the steward of the HTML specification, while WHATWG represents the efforts and interests of browser makers who must take charge of HTML implementation. The WHATWG does point to a ray of hope for extended namespaces in HTML5 that has been largely blocked by W3C: “While HTML does not allow the XML namespace syntax, there is a way to embed MathML and SVG and the xmlns attribute can be used on any element under the given constraints, in a way that is reasonably compatible on the DOM level.”
So who’s to say whose rulebook a Web site developer should follow – W3C’s or WHATWG’s?
Tristan Louis responds, “For two decades now, the W3C has been setting the standard for HTML. The WHATWG eventually agreed that the HTML5 spec ought to be led by the W3C because of that long history, and the fact that it is the only organization that works through consensus in the industry. While many complain that the W3C is slow and bureaucratic, the alternative would be a return to the pre-W3C groups when individual browser vendors could add tags without consensus, with both good and bad effects. On the good site, the IMG tag, which made the Web a rich visual medium, was created as part of the Mosaic browser and later included into HTML. On the darker side, there were as many as three different ways to embed video or other rich content into HTML, depending on which browser you wanted to target. That kind of divergence meant substantial extra work for cross-browser compatibility.”
But since RWW, and the sites Louis tested, apparently work well enough on most of the world’s browsers, and the makers of those browsers already work together through WHATWG to make certain this trend continues despite what W3C’s tool pegs as non-compliance issues… just who does all this non-compliance hurt, really?
Louis remains stalwart: “Non-compliance hurts everyone. When your browser is slower than it ought to be or when pages crash a browser, it is often because the page includes non-compliant code. The net result is that browser vendors have had to do substantial work to ensure that even bad code can run. It’s as if car manufacturers had to build cars that could ride on any surface because people didn’t bother to build bridges or roads properly.
“Today, there is no punishment for non-compliance,” he continues, “which means that, over time, we will only see further ignorance of the proper way to code for the Web, leading to increasingly sloppy offerings (I suspect that the fact that Amazon and eBay are among the older sites on the top 25 list has to do with their dismal results in terms of conformance to standards). A leaky boat, if not fixed, does not get less leaky over time.”
So the next time you click on that Like button or tweet the URL of some funny captioned cat photo to your friends… think of the damage you’re doing to the Web.
A question for you: If your site is found to be non-compliant with W3C standards, according to the Validator, whom do you hold responsible and what steps do you take?

















