Despite companies like Google making tens of billions of dollars from Web crawling, the rules governing so-called robots indexing the Web are surprisingly vague. As somebody who ran afoul of Facebook with my own crawler, I’ve taken a keen interest in other sites’ attitudes to external access. There’s some interesting stories buried in the robots.txt files that define their policies, so let me take you on a tour.

Wikipedia
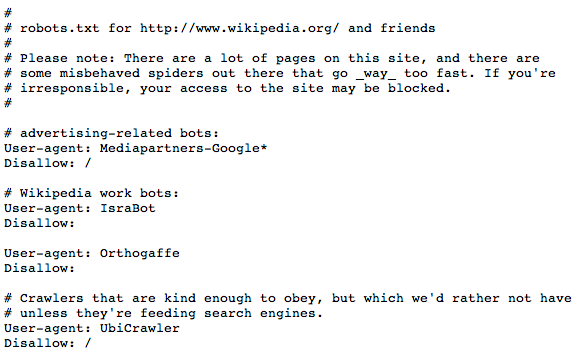
This is the only big site which makes all of its data freely available as a bulk download, without requiring a crawler or API to access, so unsurprisingly its robots.txt is a bit unusual. It’s chock-full of comments and is even editable on the main site. There’s lots of user agents that are disallowed, usually with descriptive comments about why they’ve been banned. Particularly interesting is the commentary on WebReaper, banned because it “downloads gazillions of pages with no public benefit.” This reveals the implicit deal between site owners and crawlers: the publishers put up with automated access as long as they can see the value that’s returned. In Wikipedia’s case that’s about the benefit for the general public, but for most sites it’s about their self-interest. Google sends them traffic, and other crawlers are tolerated in the hope they’ll do the same.
After experimenting with auxiliary terms of service outside of their robots.txt, the social network eventually settled on a whitelist policy. This means they disallow access to everyone, except a select group of search engines who’ve agreed to their terms. Interestingly, there are some smaller players like Seznam included, showing how keen Facebook are on competing in overseas markets. There’s also a password-protected site map that presumably makes it easy for those search engines to find and index everyone’s public profiles.
…the catch-all policy for all other crawlers has a comment that its target is “every bot that might possibly read and respect this file.” This highlights the reliance of publishers on crawlers’ good manners, and the need to spot and block the IP addresses of any that are being badly behaved.
Appropriately for a company founded on Web crawling, Google’s robots.txt is very open. The main restrictions are on service entry points like search pages or analytics. This led me to discover some tools I didn’t know about before, like its Uncle Sam U.S. government search engine, as well as some mysterious entries like the compressiontest folder whose function nobody’s quite certain of.
Probably the biggest difference between Google and Facebook is in their treatment of users’ public profiles. Whereas Facebook is very picky about who it gives access, Google not only explicitly calls out the profiles folder as accessible to all robots, it even provides a site map listing all user’s ids to make it easier to grab their information. Last year I released an open-source project demonstrating how to access these profiles, and it looks like there’s now around 9 million available, thanks to Buzz and other efforts to persuade users to open up their information to the world.
Ebay
I was surprised to see that Ebay’s robots.txt takes a similar approach to the one abandoned by Facebook, where they have a file that encourages crawling of the whole site, but includes a comment attempting to impose legal restrictions on what can be done with the information that’s gathered. This is a problem for the open Web because if it’s accepted as valid, it would require a lawyer to read and understand every single site’s terms before anyone could write a general-purpose crawler like Google’s. I believe the real answer is making some of these common restrictions machine-readable in an extended robots.txt standard, so that startups can continue to innovate without the risk of legal action from unhappy publishers.
Amazon
Unusually,
imposes more restrictions on Google’s crawler than other spiders, the only one I’ve found that does. It singles out Google to prevent it accessing product reviews, which makes me wonder if there was some dispute over the search engine’s re-use of the information on its own sites? It certainly seems like strategic information that adds a lot of value to Amazon, so I can understand why it might not want to share it with a rival. Otherwise Amazon displays a remarkably open policy towards Web crawlers. They obviously believe they get a lot of value from other people indexing the site, because its whole product catalog seems to be available for download, including prices, ratings and related product information. Their site maps even list categories like brands and authors to make it simple to access all their products.
Like Wikipedia, Twitter’s data is more easily available through other channels like the API, and its robots.txt reflects this focus. There’s also a plaintive note of despair at the bad behavior of Web crawlers that’s reminiscent of Wikipedia’s complaints. Apparently Google’s crawler doesn’t respect the crawl-delay directive, and the catch-all policy for all other crawlers has a comment that its target is “every bot that might possibly read and respect this file.” This highlights the reliance of publishers on crawlers’ good manners, and the need to spot and block the IP addresses of any that are being badly behaved.
Are there any other secrets buried in robots.txt? I’m sure there’s a lot of surprises out there, so if you’ve discovered a site with funky policies, let me know in the comments.
Photo by Splenetic

















