The future of search almost certainly involves social networks, social graphs, or social filtering in some capacity. Companies will live or die by whether they get the “social” part right: creating the right level of intimacy, trust, reliability, social connectedness, and accuracy in their results listings. Of course, this specifically means that their user experience must at least meet or, preferably, exceed that of Google’s.

To achieve this, we must first stop arguing over the different flavors of search.
Real-time search. Social search. Semantic search. These distinctions are essentially meaningless, especially when we can’t even agree on definitions and when each of their boundaries remain undefined. Instead, we should recognize that they’re all part and parcel of personalizing and contextualizing search for individual users. Let’s stop playing the “name game” and start thinking holistically about how each (and all!) affects and improves what we think of today as “search.”
Because the promise of social network integration with search is a current favorite topic, we’ll focus in this post on that: a class of social search. This is also a response to the ideas brought up by Alex Iskold in his post on the future of search.
Alex proposes that we rank search results by a kind of Social Relevancy Rank, first displaying results from friends and people whom we follow and later displaying results from “taste neighbors” and influencers, etc. FriendFeed already filters results by your friends’ content first. Twitter’s Trending Topics, by contrast, shows the crowd’s perspective. While one’s personal social circle could improve the relevance of some search results (and I noted some months back that this is a promising model), this type of filtering is more challenging than it sounds.
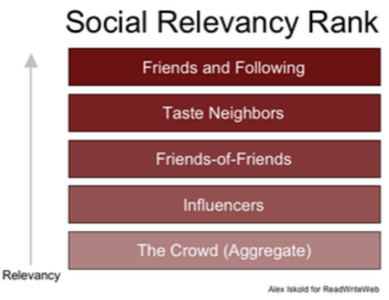
First, as Alex points out, “trusted opinions are scarce.” Our friends couldn’t possibly know everything we’re interested in, and the smaller our social circle, the worse the problem becomes. Even with large social graphs, sooner or later we will undoubtedly search for a topic that hasn’t been indexed in our friends’ activity streams, and then we’ll get few to no results and suffer an inferior user experience. We’d be better off turning to good ol’ Google… the very thing we’re trying to best!
Secondly, getting Social Relevancy Rank right involves a lot of insight into what users care about. Alex comments that, “This is not difficult for FriendFeed to do because… it knows who you care about.” But does it? On FriendFeed, I follow only a limited number of the people I actually care about. Do those people alone account for the things I care about? And when I perform a search, does the engine know what I’m caring about at that moment? True, we have to start somewhere — as PageRank did — and tweak the algorithm over time. But suggesting that even a smart Social Relevancy Ranking is clued in to what we care about at any given moment is presumptuous at best given the state of the art.
Yet, having different levels of social relevance is a good theory, and Alex’s demarcations are sound, in essence. But each level more likely indicates degrees of social proximity than relevance per se; although in some cases closer proximity may very well indicate greater relevance. The problem is that relevance is highly contextual. It depends on many factors, such as your profession, your search query, your friends, your friends’ knowledge about those topics, and the information that is publicly recorded in their activity streams.
For example, a financial analyst (i.e. an expert) wouldn’t care if her closest circle of friends was Twittering about how complicated a new tax code is. As an expert, she’d rather know exactly how the new policies affect an edge-case client of hers. Filtering search results by “friends and following” at one end and “the crowd in aggregate” at the other may fail equally in uncovering the right piece of information for her.
For general users, the “it depends” factor may be the urgency with which information is needed. When the need is urgent, people will actively search for the information (in any number of ways); other times, information may be welcome but only encountered serendipitously or consumed passively. Browsing feeds, Twitter posts, and Facebook streams are all passive ways of discovering information. Putting these activities on a continuum in which information search is active but information discovery is passive could look like this:

But to actually achieve a “Social Relevancy Rank,” we have to consider how layers of social proximity map onto this search-discovery continuum.
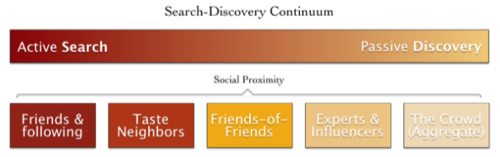
When people actively look for a piece of information (e.g. the best Barbary Coast Trail guide for tomorrow’s hike), they likely require trustworthy, high-quality information that could at least inform their decision. “Friends and following” could serve as a reliable social filter at this stage. But as the urgency subsides (e.g. just poking around for a mint julep recipe a week before a get-together), we relax our requirements and even welcome a wider set of results. At this stage, filtering results by friends of friends, influencers, experts, and even crowds in aggregate is appropriate.
Of course, serendipitously discovering information from “friends and following” would be welcome in other instances. So, to actually improve social relevancy in search engines and discovery services, there would have to be a distribution of acceptable social filters whose levels depend on how active the user is and what the user is searching for:
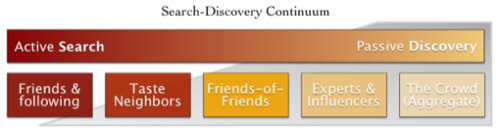
What this still fails to address, though, is how to assess the urgency of a user’s needs or how to derive that level of urgency from the user’s known behavior. This is a problem that engineers, designers, and HCI researchers have been struggling to solve for a long time (and a million dollars will get you only so far).
The problem of effective search runs deep. You can have all the flavors you want — social, real-time, semantic — and tomorrow’s flavor will be merely another riff on the same tune. Yes, social networks and the social graph have the potential to meaningfully filter millions of otherwise undifferentiated pages of results. But words like “meaningful” and “relevance” are so contextualized — varying as they do from user to user and usage case to usage case — that they can’t be expected to mean anything unless they are anchored by context. Mapping social proximity to users’ active and passive information consumption could help us create more contextualized user experiences on the social Web, resulting in less time spent naming the latest flavor of search and more time spent actually improving search.
Guest author: Brynn Evans is a PhD student in Cognitive Science at UC San Diego who uses digital anthropology to study and better understand social search.