The open source NoSQL graph database that has perhaps attracted the most attention in recent months has been Neo4j, a Java-based DBMS with a RESTful API that supports multiple languages. Earlier this month, Microsoft embraced Neo4j by enabling its use through the Windows Azure cloud platform, whose .NET languages aren’t typically associated with Java.

Now, a new commercial distribution of Neo4j premiering this week from Spring Data adds a head-turning new feature for developers: a mapping mode that enables data to be accessible as ordinary Java objects. This means new Java developers won’t have to learn the quirks of Neo4j’s AspectJ library to access data much the same way they’re already doing for Oracle and MySQL Connector/J.
For database access libraries, a mapping mode is one way that a schematically defined set of data can be addressed by a procedural language, step-at-a-time. In other words, not by a SQL command like SELECT but by assignments to variables or members of collections
Neo Technologies CEO Emil Eifrem explains graph database schemas in an April 2010 discussion at Microsoft headquarters with blogger Robert Scoble.
“Neo4j 1.0 had a very powerful mapping mode based on AspectJ technology,” explains Emil Eifrem, lead engineer of Neo4j and CEO of Neo Technology, in an interview with RWW. “It turns out that when we talked with enterprise users out there, AspectJ was not yet widely adopted by the enterprise. So what [Neo4j] 2.0 does is provide a completely new mapping mode that makes it as easy to access Neo4j as to access Oracle and MySQL.”
It’s the culmination of a ten-year effort, says Eifrem, and is not the kind of engineering that just any company can bolt on with a few months’ work. Essentially, it’s a double-translation, using the process that would normally translate the image of data from traditional relational tables to procedural functions, and extending it to translate graph databases to procedural functions.
In a traditional relational database, the relations between fields are presumed self-explanatory. A customer has a first and last name, and address, and some contact information. All that goes into a table, explaining what an RDBMS engineer would call a first-order relation. A customer orders a product, which is explained by a record in a second table. That forms the second-order relation. An invoice is produced based on all the outstanding second-order relations for that client at a given time. Some call this a third-order relation.
All that seems appropriate for most jobs, up to a point. We know why invoices are related to customers and products. All that is presumed, and specified in the schema. But what about cases where the relation between two columns is not a state, but rather a variable? For example: What are the closest restaurants to my present location? What are the highest-rated restaurants close to me, in order of distance? What are the least recently visited, high-rated restaurants, in order of distance? These queries are indeed representable by a traditional database, but as the size of the problem scales up linearly (as cloud-based maps of every public building in the world tend to make it do), the inner joins and other processes used in generating conventional subsets of data results consume more time exponentially.
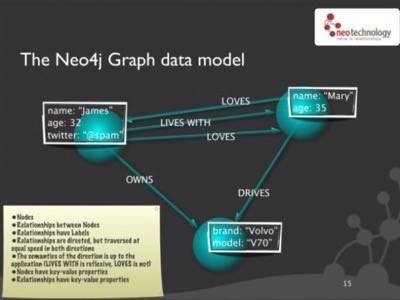
This problem is already solved in its entirety by the graph database model, which is a more geometric approach to modeling variable relationships. Unlike the RDBMS model, nodes in a graph database are associated with one another qualitatively. Not only does an association between nods state that a relationship exists, but also describes how. This way, the process of joining nearby restaurants to ratings and ordering by proximity, and others like this, change from complex reorganizations, joins, and sorts to something that Emil Eifrem literally describes as “trivial.”
“When we started talking to enterprises about what they require from databases, we got three main things. One is a very rich data model,” reports Eifrem. In a veiled reference to Oracle’s new NoSQL data store, he continues, “There’s a bunch of key/value stores out there, for example, which have a very simplistic data model. That’s great for some things, but most of the data inside of the enterprise is very complex.” He cites the massive, and growing, databases centered around network management, content management, property and asset management, relationship management (CRM, ERM), all of which are emphasized by the connections between data and the complexity of their interrelationships. These map most poorly to key/value stores.
Enterprises also said the database needs to support transactions — atomic-level processes which enable consistency across multiple users, and which can be rolled back or undone without damage to the data sets. “It’s never okay if you’ve killed the database after you’ve stored data, and the data disappears,” says Eifrem matter-of-factly.
Third, and by Eifrem’s measure most importantly, is the emerging fact that most enterprise applications are written in Java. There’s great momentum behind Ruby, Python, Scala, and don’t forget PHP. But the other 90% of functionality, he says, is Java. “If you want to catch on in the enterprise, you need to have great Java support.”
While key/value store technology — the core of the NoSQL movement — has its roots in Web-oriented technologies and consumer-facing companies such as Google and Yahoo, Eifrem says, Neo4j’s roots come from the enterprise. Specifically, it dates back a few years to a phone call from Cisco. As Neo’s CEO relates to us, Cisco was in the process of building a master data management system — a project that began with an Oracle rack five years earlier. “They were just banging their heads on this one problem, because their master data management system had a lot of complexity, and the joins were just killing them. For whatever reason, they had found us, downloaded Neo4j, and found a thousand times better performance than what they had.”
It was the start of a beautiful friendship. Now Cisco teams up with Neo Technologies in giving lectures to the open source development community on the flexibility and performance of graph databases.
“This was pretty crazy for us. We’re six guys in a garage in Malmo, Sweden,” says one of those guys. “And we have this Fortune 50 company betting a mission-critical system on us. If this system goes down, they have to write invoices by hand. This, to me, was a huge indication that there’s a lot of pain out there, and a lot of pain inside of the enterprise.”

















