
External data can be used to improve overall business performance. First, however, dig deeper into the way external data is sourced and implemented into management practices.
External data is increasing in utility yearly. As acquisition becomes more ubiquitous and accessible to smaller businesses, applications for external data proliferate. Proper management of such data, however, continues to be an issue. A survey conducted in the past few years has shown that even legendary enterprises can struggle to manage data.
Before continuing, I highly recommend reading my previous article on this topic. Jumping into external data and its acquisition and management would be easier if the proper groundwork was already laid.
Understanding External Data
It may sound simplistic at first. However, external data is all data that is acquired from outside the organization. In marketing, it’s often referred to as second party or third party data.
However, external data arrives in many shapes and forms.
We should make three critical distinctions between traditional external data, advanced external data, and alternative data. First, most of us are familiar with traditional external data sources – government records, statistics departments, press releases, etc.
While comparatively few businesses have heavily employed it, traditional external data still found its place within the financial industry and several others. Advanced external data, however, aims to attract a much wider audience.
Advanced external data is produced through internet monitoring and automated data collection.
Many businesses use some measure of advanced external data such as social media sentiment analysis or tracking and monitoring customer reviews.
Finally, alternative data is not as much of a new type of data; it’s rather a quality. While there are many definitions of it, it’s usually understood as the opposite of traditional data. In other words, it’s taking data that hasn’t been used often and deriving actionable insights from it.
An excellent example of alternative data is satellite imagery. Again, it may come as a surprise, but there’s a fairly direct use case for the financial sector for such data.
Researchers have found that satellite imagery of retailers and other significant market participants can allow investors to deduce value fluctuations before everyone else catches up.
In such cases, alternative data can be used to make better investment decisions.
Integrating Advanced External Data into Existing Pipelines
External data requires some dedication, unlike internal data, which is mainly collected as a byproduct of other business processes. It can only be acquired through creating in-house data collection teams or by sourcing it from third-party providers.
However, before any web scraping or automated data collection can even begin, three things need to be decided: what kind of data is required, how it will be implemented, and where it will be stored.
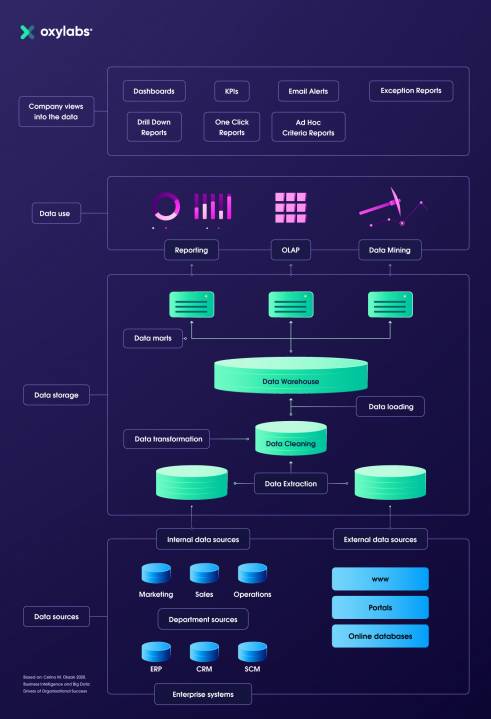
As I’ve mentioned in my previous article, data warehouses should be the place where all business data arrives. However, that only applies to data that is not being used for daily operations. External data can power both day-to-day operations and be used for more long-term purposes.
If the data is being collected for daily operations, such as for dynamic pricing, the information might never end up in a warehouse (or end up differently). In these cases, long-term storage will likely be an afterthought as dynamic pricing will be a complex web of APIs, mathematical comparisons, and computations.
How advanced external and alternative data can be understood
On the other hand, some advanced external and alternative data can only be understood if stored and analyzed in relation to additional information. These cases are more complex and require significant planning.
First, all of the data collected should have a particular purpose. Usually, that purpose will be to support or deny a hypothesis. Going back to our example of satellite imagery, such data would need to be stored longer-term and analyzed manually. It should be assigned a specific subject and expectation.
Second, it should be understood that alternative data might not turn out to be useful in some cases. For example, since it’s usually data that is hypothesized to provide insights into some particular phenomenon but hasn’t been tested thoroughly, alternative data might be found to be unable to support the proposed hypothesis.
Finally, external data collection processes require more maintenance and support than traditional ones. If the business does not already have a dedicated analyst or extraction team, using advanced external or alternative data will be difficult.
Building Support Structures
To make use of advanced external and alternative data, support structures need to be built. In some cases, they can be pretty simple if the data is acquired from a third-party vendor. Only a data analyst team and some governance practices will be required. But, of course, data quality vetting and other processes will still be required.
Things get even more complicated if no data vendor can provide the necessary information or if an in-house scraping team has to be established for other reasons.
Since in-depth technical development is something I trust my colleagues on, I will skip over the nitty-gritty details. Instead, finding a vendor that provides scraping solutions is the easier choice for most businesses.
Still, a proper integration will require a dedicated data team to take care of the flow, especially if the information is collected from multiple sources. At least three crucial steps will have to be undertaken before the data can be moved to a warehouse: cleansing, normalization, and assurance.
Data extracted automatically from multiple sources won’t be unified, there will be possible corruption, or it may simply be inaccurate.
Therefore, data cleansing will need to be performed. After that, data has to be normalized before it can be moved anywhere. Usually, that is essentially fixing formats, naming conventions, and other structural aspects.
Finally, quality assurance is necessary before it can be moved anywhere, even though, unlike with some other types of data, scraped data will often have the quality required as it’s decided beforehand. In cases where some data is acquired from a vendor, quality assurance becomes significantly more important.
Conclusion
Once external data gets involved in the pipeline, things get exponentially more complicated.
Costs also increase as automated data collection requires either technical expertise or analytical capabilities, or both. As such, integrating external data into business processes has to be carefully planned in advance.
However, the benefits reaped through external data are tremendous and open up entirely new growth opportunities.
Image Credit: George Morina; Pexels; Thank you!

















