
For many enterprises, Big Data remains a nebulous goal, rather than a current reality. Yet it’s a goal that more and more enterprises are pushing to the top of their priority list. As Gartner surveys have shown, everyone is keen to board the Big Data bandwagon, yet a comparative few really understand why. And as Gartner analyst Svetlana Sicular points out, the myths that hold back Big Data adoption vary depending on where along the adoption curve an enterprise happens to be.
In 2014, many of the sillier Big Data myths will crumble to be replaced by increased experience with data-driven applications.
A Phased Approach To Big Data Ignorance And Enlightenment
No one goes from Big Data newbie to sophisticate in one go. This is why an agile approach to Big Data projects is so critical, as I’ve written here and earlier presented at Strata Conference. Failure is a given. The key is to minimize the cost of failure, which is why open-source technologies like Hadoop are so critical to Big Data success.
Sicular presents the journey to advanced Big Data success in this way:
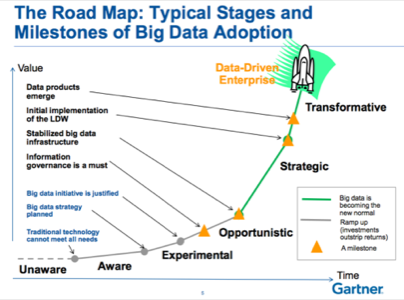
Along the way, she notes, the myths that impede our progress change.
Rookie Mistakes: Volume, Hadoop and More
The first set of Big Data myths Sicular identifies come down to core misunderstandings as to what Big Data means, and the consequent confusion as to the right technologies for the job.
For example, the first Big Data myth Sicular identifies is the persistent belief that Big Data is a matter of data volume. The reality, she finds, is much more nuanced:
Big data is high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making
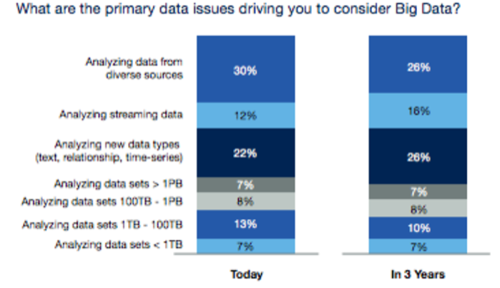
Indeed, as a variety of studies have shown, including this one from NewVantage Partners (shown at right), clearly indicate that for most Big Data projects, velocity and variety of data are the most important characteristics.
As such, another persistent myth—that Big Data is all about Hadoop—keeps enterprises from exploring the technologies that more logically fit actual Big Data use like NoSQL technologies (for real-time processing of disparate data types) and “logical data warehouses,” completing the technology stack Sicular urges enterprises to consider.
Beginners At The Big Data Gates
Once enterprises have moved beyond these rookie mistakes, they’re ready to tackle more advanced myths. At this “Aware” phase, enterprises have a better understanding of which data matters to them and how to process it, but they make the mistake of believing that all of their problems can be solved if enough data is applied, and falsely suppose that their peers are far ahead of them.
Hence, Sicular isolates Big Data problems to those “business problems where questions are not known in advance and the data types to answer these questions could vary and might need unstructured data.” In other words, Big Data is useful when you may want to store data first, and query it later. If you know what questions to ask of your transactional cash register data, which fits nicely into a relational database, you probably don’t have a Big Data problem. If you’re storing this same data and also an array of weather, social and other data to try to find trends that might impact sales, you probably do.
Which is not to say that the only data that matters is the unstructured data outside one’s enterprise. In fact, the opposite may be true. As Sicular posits, “Dark data—i.e., underutilized data in existing data stores—is of greatest interest to all enterprises who investigate big data opportunities.” When asked which data enterprises currently analyze, transactional data and log data were the top-two responses.
Much of the most interesting data is already sitting on mainframes and in relational databases within the enterprise, but has been poorly managed in the past. Big Data projects often should start with the data already available but isn’t being put to effective use.
Experimenting With Data
Sicular’s third phase sees enterprises actively experimenting with their data, but still flummoxed by a lack of skills and immature technologies. It’s at this phase that enterprises turn to the mythical data scientist, and discover both that she’s hard to find and isn’t necessarily the right person for the job, anyway.
Rather than focus on finding a “data scientist,” Sicular urges enterprises to staff a “multidisciplinary team with diverse skills [to] meet technology challenges and solve complex business problems of big data adoption.” This is critical given the importance of asking the right questions of one’s data. Context matters, and different people bring different ideas of how to think about one’s data.
Big Data Experts … At Last
The later phases of Big Data adoption are filled with some unexpected realities – that Hadoop is not as cheap to implement as some would hope, that enterprises tend not to take advantage of commodity hardware and instead buy expensive machines, and more – but also some nice surprises, like the fact that Big Data technologies are relatively easy to program against.
Interestingly, the further along enterprises go, the more they realize just what a treasure trove their structured data is. While unstructured data may account for 80% of data volume, for now it’s not nearly 80% of Big Data value. As Sicular notes, “Structured data has been refined and its density and quality are much greater than comparable amounts of unstructured data.” This will likely change over time as Big Data technologies get better at managing/ordering unstructured data, but it’s a reality today.
All of which serves as a reminder that much of what we believe about Big Data may not actually be true. As such, approaching one’s Big Data projects with a measure of humility is crucial.
Lead image courtesy of Shutterstock.

















