
The discussion of big data technology can often be split into one side or another: the realtime capabilities of databases that often have to organize records at sub-second speeds, or the analytical capabilities of databases that have to comprehensively search those same records at the same level of speed. Sometimes it takes a product like
to remind technologists all that these two topics are still two sides of the same big data coin.
It’s an easy mindset to fall into, according to Jonathan Ellis, CTO and Co-founder of DataStax, because it’s easy to perceive the demands of realtime and analytics fighting each other. This is especially true when performing scaling operations.
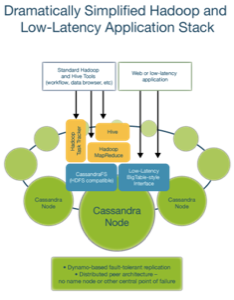
When scaling up, for instance, every added node to the analytics database means that the realtime database traditionally has to be replicated (or vice-versa), a time-consuming process at best. Scaling out to multiple locations isn’t fun either, with hugely complex extract, transform, and load processes the norm.
Brian Proffitt is a veteran technology journalist, analyst, and author with experience in a variety of technologies, including cloud, virtualization, and consumer devices. Follow him on Twitter @TheTechScribe and Google+ at +Brian Proffitt.
That’s just part of the problem that Brisk works to solve, Ellis explained, by reunifying realtime and analytics with the merger of the Cassandra realtime database and Hadoop analytical technology. Essentially, Brisk is a self-described Hadoop distribution that replaces the Hadoop Distributed File System (HDFS) with Cassandra’s CassandraFS and throws in the data query and analysis capabilities of Hive in for good measure.
The result is a flexible big-data platform that can handle large-scale transactional and analytical datasets at the same time.
Ellis is well-suited for working with Cassandra: he’s currently the project chair on the Apache Cassandra project. He’s also done a lot of filesystem work, having “built a multi-petabyte, scalable storage system based on Reed-Solomon encoding for backup provider Mozy,” according to an online bio. While he comes across as laid-back, you can tell he’s pretty passionate about Brisk and what it can do.
First off, the replacement of HFDS with CassandraFS takes care of one of the big known problems with Hadoop: the single NameNode device that’s at the heart of any Hadoop architecture. The NameNode is the single point of control for any HDFS deployment, and is widely regarded as one of Hadoop’s biggest obstacles for deployment, despite Hadoop’s other capabilities. CassandraFS, which is fully compatible with HDFS so any Hadoop add-ons will also work in Brisk, solves the single-point-of-failure problem at a stroke.
Brisk also helps organizations manage the problems inherent in scaling data out, which precipitated the move to non-relational databases in the first place. Relational databases, Ellis explained, have their place, but they are very difficult to scale (up or out) and “the pressure to scale out is becoming a mainstream need,” he said, primarily due to the pressure for more and more Software as a Service (SaaS) deployments.
Scaling is something a nonrelational database like Cassandra is very good at. In a SQL-based database, any replication failure means databases have to be rebuilt. For DBAs, Ellis said, it’s pins and needles at this point, “because if the primary dies, you’re screwed.”
Cassandra’s replication methodology, however, means that the data never has to be replicated from scratch. Ultimately, that means that when a node is added to a Brisk cluster, it will automatically and seamlessly be replicated and merged into the cluster.
“Think of it as an rsync for databases,” Ellis elaborated, referring to the file replication software project in Samba that’s popular on Unix and Windows systems.
Cassandra is not the only big player in this story; Hadoop brings some much needed features to the table as well, most notably the capability to handle data joins, something beyond Cassandra right now.
Ellis sees Brisk as the first true second-generation distributed database, asserting that other databases, such as Hbase and Voldemort, have their roots directly in their forebears, BigTable and Dynamo, respectively. While not disparaging these databases, Ellis believes that Brisk represents a true innovative departure from this first generation of databases.
Having a single distributed database system that can handle both the realtime and analytical sides of the big data coin is going to be an attractive proposition for SaaS and cloud providers looking for simplified solutions to their deployment needs.

















