Hundreds of thousands of websites are using a new service to track when readers copy and paste content from their sites into an email, blog post or elswhere. The service, called Tynt, isn’t just making sure that credit is given where it is due – it’s tracking what content is of interest to readers… right down to the word.

Tynt says that people copy and paste content and links 50 times as often as they click on sharing buttons to post to networks like Facebook and Twitter. Now the company is opening up a series of Application Programming Interfaces (APIs) that will allow publishers to track automatically what particular words readers on their site are interested in. That data has incredible potential, but it’s not clear it will be used in ways that befit the opportunity it presents.
You may have seen a link back to a source page inserted into text you’ve pasted somewhere – that’s Tynt. (Many people hate that, very much. See comments on this post for example.) The company may not be known well to Web users, but we are known to it – Tynt says it has now placed more than 1 billion tracking cookies in the browsers of people who have visited a page that uses its service.
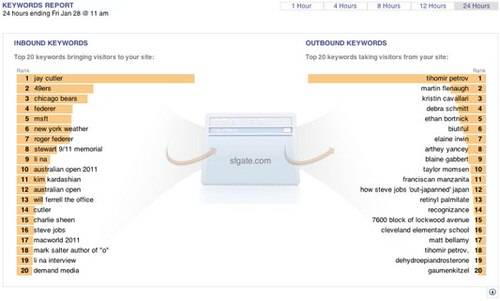
The numbers clearly show: The people want more Kim Kardashian content! Because ravenous consumption of raw human souls would be uncouth.
Why Tynt Makes Me Sad
For many people, Tynt’s insertion of links back are so annoying they consider the company a hostile parasite. There are problems beyond that, though.
Services like this, and I say that broadly because I’ve not seen anything else quite like Tynt, tend to focus on website publishers because they believe that’s who will pay for this kind of information. Apparently some publishers don’t really know what kinds of content their readers like – but if they found out, they’d publish more like it.
That’s understandable from a business perspective, but it’s also a little sad. Ought publishers not publish the best content their editorial team is capable of and interested in, according to their editorial brand’s unique voice? There’s something about publishing on such scale that the interests of your readers isn’t obvious, and then making editorial decisions based on sheer numbers, that seems sad to me. Call me a small fry in the publishing business, I guess.
Meanwhile, the data that Tynt offers seems like it ought to be of interest to far more people than just publishers. What about application developers and others who would like to use this data to rank content from other sources? If copy and paste is really 50 times more common than sharing on Twitter and Facebook, then I would think that data would be invaluable for ranking content from third parties.
We’ve written about sharing services ShareThis and AddThis, both of which already have large sums of money invested in the content sharing data as a platform. Tynt seems likely to have far more data, and data more representative of mainstream email users instead of just social network sharers.
What will become of all this data, though? Will it just be used to steer editorial decisions in a way that panders to what people already know they want? Or editorial that leads, through discovery of things we don’t know about yet. Will it be used to target advertisements? That may not be bad – but it’s not very exciting either.
What if we get a look into the Web’s collective consciousness and all we see is advertising opportunities? Services like Tynt seem like they inhabit a strange place – between an area of great generative potential and a dark and unpleasant place. (Maybe that’s just the name, I don’t know.)
What would you like to see done with data about what millions of people are copying and pasting? It’s time we had that conversation, before this opportunity not just for one company, but for the Web in general, is lost.

















