With advance apologies to the hard-working PR folks and startup companies who have pitched us their social search engines this week, there is a rising menace in new media: A cluster of sites that call themselves user-powered search engines.

Much in the vein of the failed Wikia Search (the abandoned brain child of Wikipedia founder Jimmy Wales), these engines purport to “crowdsource” intelligence about URLs and search terms by allowing users to create profiles and submit, submit, submit content. Stumpedia and Gurutoy are two products in this category. Each offers the excitement of multimedia, semantic, “neue search” capabilities; and each delivers astonishingly dysfunctional results.
Exhibit A: Stumpedia
Stumpedia calls itself “the human-powered search engine… a personalized social & real-time collaborative search engine that relies on human participation to index, organize, and review the world wide web. Stumpedia does not depend on bots, algorithms, or company insiders to make decisions on the relevance and ranking of search results.”
Because god knows those algorithms have done nothing for search in the past. As for the “company insiders” part, we’re drawing a blank on precisely what that means (Megan McCarthy, was this aimed at you?) and defer to the wisdom of the all-knowing RWW commenters to fill us in.
Stumpedia currently boasts around 28,000 URLs and 75,000 search terms in its digital lexicon – hardly enough to allow for a good or interesting browsing experience. By way of comparison, Wikia Search had indexed about 30 million websites before Jimmy Wales could say with a straight face that the product didn’t suck. Just because we know he likes the attention, we ran a search on Robert Scoble:
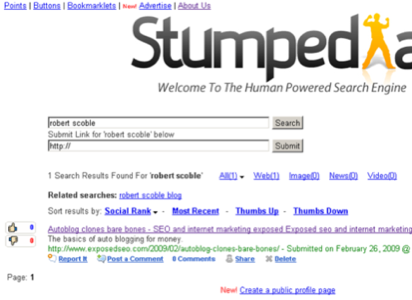
As you can see, the single returned result was entirely irrelevant to the search term; Scoble’s name was nowhere to be found on the linked-to page.
And sadly, for all the talk about insiders not gaming the system, the most relevant results in many searches we tried came from the Stumpedia founder/CEO. Here’s a look at his profile and submissions:
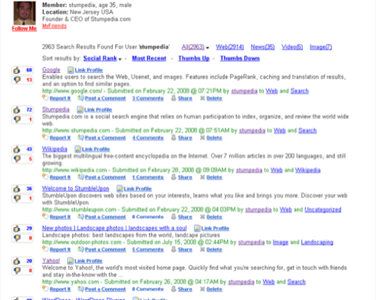
We wanted to run a search for irony, but apparently the CEO hasn’t submitted anything ironic lately.
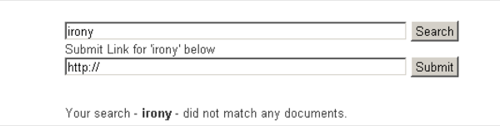
Exhibit B: Gurutoy
Gurutoy recently appealed to us for coverage, styling itself “a visual search engine run completely by you.” According to its homepage, Gurutoy asks users to “tell us what is cool and interesting in the worldwide web, and it’ll be posted up in Gurutoy for others to see. Search Gurutoy using keywords and phrases and you’ll see an array of websites uploaded by you and other users.”
Assuming that the 99 percent of Internet users who are not tech bloggers use search engines because they need to find accurate, relevant results, the bar of expectations rests rather high.
For example, if a user searches for “orange juice,” he might not expect to see this:
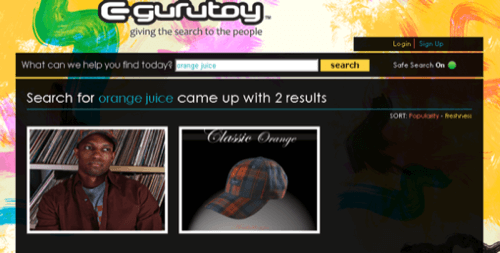
As can be seen by mousing over the thumbnails, the two results returned for that search term were both uploaded by a Los Angeles haberdasher. The results were tagged with relevant (“plaid,” “headware”) as well as damn perplexing (“brad suzuki,” Gurutoy’s CEO) terms, and we’re still not sure how this cap was returned as a result for “orange juice.”
Distressingly, a recommended search for “action figures” returned dismally irrelevant results:
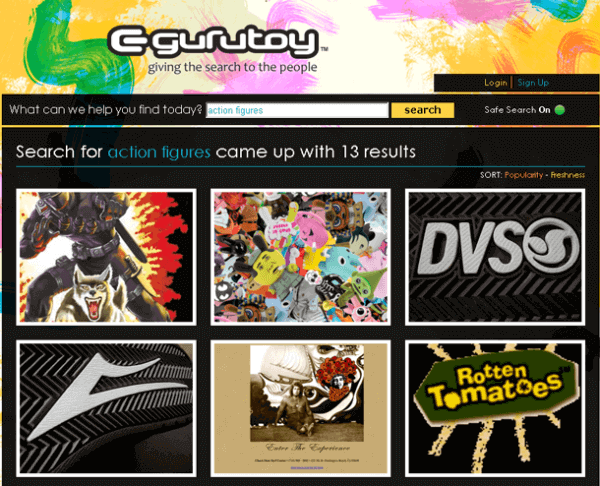
Two of the 13 featured results had information on action figures, and none of the images contained action figures.
The Problem with Reliance on UGC
When thinking about building a “visual search engine,” entrepreneurs must consider the relevance of the images as well as the URLs. They are faced with the reality of competing with Flickr and Google Images, both of which have powerful tech backed up and fed by a critical mass of user-generated information in the form of tags. They also must compete with Google, Yahoo!, and Microsoft Live search engines on the relevance of results’ content.
Expecting that users will do the kind of data entry necessary to create a competitive product in this arena is ludicrous. The Internet already has a Wikipedia, so the kind of people with the knowledge and skill sets and the sheer time to invest have likely already picked their hobby and are eyeball-deep in barnstars.
However, Suzuki sees it differently: “The goal of Gurutoy is to become a visual directory of websites (any subject) on the net. But in a cool way, with the pictures.” He compares the site to YouTube and has every faith in the power of user-submitted content.
“Gurutoy does not use any spiders to search the web for content. What we’re counting on is for the masses to catch on with Gurutoy and to grow the content to make it relevant.”
I asked SproutBox cofounder and venture tech/capital expert Mike Trotzke what he thought of algorithm-free social search engines.
“Oh, you mean a purely spam search engine with no users? Yeah, they suck.
“If you are going to try to introduce UGC into search engines, you’ve got to have some indexing first. It has to have some value out of the gate or no one will care. Not even Jimmy Wales could pull that off.”
Trotzke continued to say that if any company would be able to incorporate valuable user-generated information into search, it would be Google. And he doesn’t imagine that the search giant would be interested in buying a smaller company for their data or technology.
“[Google has] the vote-up technology already ready in waiting. They just need to tweak and start giving weight to all the data they have been collecting in SearchWiki notes for months already.”
The Spam Question
In Social Media 101, we learn that where there is user-generated content (i.e., where anyone is allowed to tag and submit unreviewed content at no charge), there is spam.
Right now, most of the “users” interested in submitting content to these sites are retailers, enterprise sites, or others with a vested fiscal interest in driving traffic to their URLs. As you can see in this screenshot, MyJewelersPlace.com is spamming the heck out of Stumpedia:

Any site that permits user-submitted links is going to suffer the predictable, lamentable onslaught of black-hat, link-stuffed atrocities, especially for competitive verticals (I personally dare you to search any of these sites for iPods or Viagra.) Especially when adoption rates are low to begin with, UGC search engines are at high risk for being overrun by this kind of spam. This begins a circular process wherein potential users are scared or bored away from the site when search results are irrelevant, desperate pleas for clickthrus and credit card information.
For generic, noncommercial queries, few or no results will be returned. For more consumer-minded searches, results will be skewed and often uninformative. Allowing the community to police itself by flagging suspicious content is a necessary feature for any UCG site. However, when the amount of spam already outnumbers the amount of useful content on a relatively new search platform, what users are going to stick around long enough to register an account, let alone slog through the spam, planting flags left and right.
So, with more apologies to the startups named above, social search still needs to amass and index content using traditional search algorithms if results are to be useful to the end user. Then again, you could just let Google have this one and wait for your next big idea.