With the announcements of Facebook’s “frictionless sharing” and Amazon’s Fire color Kindle, my colleagues Joe Brockmeier and Richard MacManus have both weighed in on their thoughts about where the modern Web is going. I think both opinion pieces hold some worthy points, but I have my own fears and thoughts. It comes down to whom do you trust more to own your data: Facebook, Google or Amazon. And while there are other choices (notably Microsoft and Apple, plus numerous smaller entities), my conclusion is that none of Big Three has the ideal set of circumstances here.

In the ideal world, I want Amazon’s recommendation engine and cloud Google’s transparency and identity tools, and Facebook’s content well all mashed up, to give me the best of all possible worlds. Sadly, we are stuck with the wrong kind of mashup: Facebook’s privacy controls coupled with Google’s poor API documentation and Amazon’s scatter-shot notions of content controls.
The problem is that unlike choosing where you live, it isn’t a binary choice of owning your own digital home or renting from someone else: your Web data and identity is spread across a vast, complex and ever-changing landscape. You might own one or more domains that use one or more Web services, such as blogs and content aggregators. You might rent a blog on WordPress.com or host your own blog using their software on your own server. You certainly rent your data from Facebook and other free social networking services. You don’t own it. And there are other dimensions, such as the digital tracks that you leave around the Internet with your searches, your purchases, your uploaded content and your conversations.
All this means that there are three dimensions to this notion of data ownership and trust:
- How transparent is a vendor in what they collect on your actions and activities?
- How easy is it to extract this data to be used elsewhere, should you grow unhappy with anyone’s particular terms of service or policies?
- Who owns which part of your digital identity and what are the privacy implications of that ownership?
Let’s look at the Big Three and see how they measure up in each of these dimensions.
Google’s Dashboard
Google has done the best job of being the most transparent, with its Dashboard. In one place, you can see just about every interaction with their stuff: your searches, your Gmail emails, your collection of Picasa photos, your books purchased with their service, what blogs you have with Blogger.com and more. It is both sobering and somewhat disquieting to see how much of your electronic life is contained within the Googleplex. But at least you can go to one place and see the landscape readily.
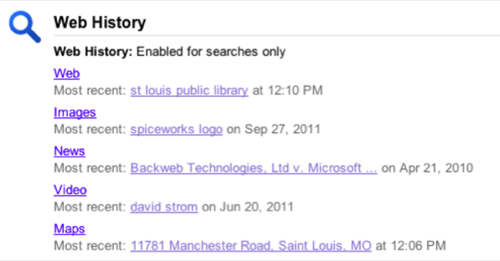
Extracting this data is somewhat of a mixed bag. Not all Google services have well documented APIs or extraction tools: Gmail’s contacts, for example, will get you a CSV file with all your names, but none of the social graph, as it were, of what lists and other categories you have placed these names in. Or G+ just recently got its own API, but that doesn’t mean that you have much control over how you can resurface that content elsewhere.
And when it comes to trusting Google with my digital identity, I do trust them, but somewhat warily. I use Google to host the email services on several of my domains, but I do that because they are free and they are good at it. But if someone else where to come along that had something better, I might consider switching.
Amazon
Amazon is very much a mixed bag and a work in progress from being an e-merchant to being a major Internet data owner. That is both their opportunity and their challenge. They already know what books I read and can recommend something that I might like, and have a great reading ecosystem that is crushing local bookstores, something that as a supporter of our local bookstores pains me to no end.
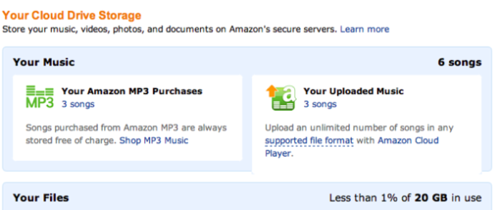
But aside from the books, Amazon is already a big factor in other parts of my digital life. They offer DRM-free music, so I generally purchase my tunes from them rather than give Apple any more of my money. They have a great deal of transparency on what data on me that they have, but I have to look in separate areas in my account to see these collections.
Yes, I can extract some of this data, but again, it isn’t easy. You can run reports against your orders and download a CSV, but that CSV doesn’t tell you what you actually ordered. You can save any purchased music content in the cloud and download to another machine, but again that isn’t smooth.
Of the Big Three, unless you are a rabid book reviewer, Amazon doesn’t have much to do with your digital identity. That will change as they include their own browser on the newer Kindles that will track your searches and cache your Web content. And no one yet knows whether this information will be available to you outside of their ecosystem either.
Finally, we come to Facebook’s ever-shifting landscape of privacy and content. I agree with Joe that you need to start hedging your social media bets and spreading your content around to other places. But I also see the perspective of some of our social media natives on our staff who get almost as much content from others in their social graph than they give, and I congratulate them on this achievement.
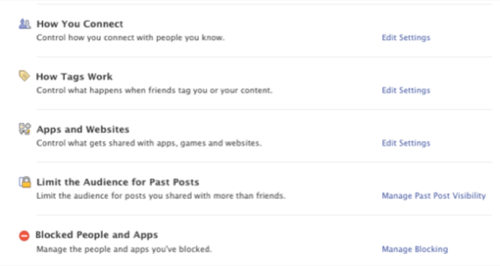
But Facebook owns my social media identity on their system, and as many commentators have stated, you can’t really get it back. Yes, there are some ways to extract my social graph, and I can use services such as OX.IO and Nimble.com to synchronize and analyze who is my Facebook friend, and the enhancements this week allow me, if my time and patience allows, to stratify my vast network of friends into the folks that truly matter and those that are just hangers-on.
Each of the three has its strengths and drawbacks. And sadly, we are stuck with this mish-mash of tools and services to manage our data for the time being. Maybe moderation isn’t such a bad idea after all.

















