MySpace has taken a bold step and allowed a large quantity of bulk user data to be put up for sale on startup data marketplace InfoChimps. Data offered includes user playlists, mood updates, mobile updates, photos, vents, reviews, blog posts, names and zipcodes. Friend lists are not included. Remember, Facebook and Twitter may be the name of the game these days in tech circles, but MySpace still sees 1 billion user status updates posted every month. Those updates will now be available for bulk analysis.

This user data is intended for crunching by everyone from academic researchers to music industry information scientists. Will people buy the data and make interesting use of it? Will MySpace users be ok with that? Is this something Facebook and Twitter ought to do? The MySpace announcement raises a number of interesting questions.
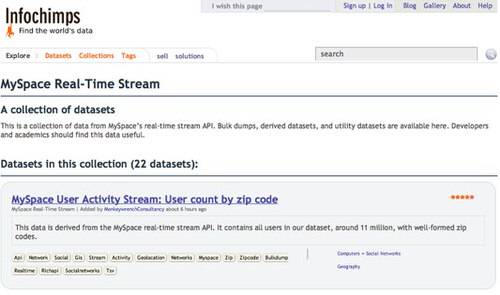
The 22 sets of data being made available are cheap. Prices range from $10 for raw dumps from the MySpace API to $300 for everything broken out by latitude and longitude. Subsequently derived data sets can be put on sale by InfoChimps users as well, with a revenue split.
Analysis coming from the data could include things like music trends per zipcode, popular URLs being shared, etc.
MySpace is generally thought of as a social network on the decline, but if it is able to position itself as the place to do music still then its hundreds of millions of users could remain engaged. Will data scientists want this data, though? Time will tell, but MySpace has long done cooler things with data than competitors Facebook and Twitter and people haven’t gotten terribly excited about it yet.
Related: See today’s coverage of the cancelation of the Netflix Challenge due to privacy concerns.
Bulk user data has tremendous analytical potential and both Facebook and Twitter have thrown the breaks on 3rd parties offering up their user data more than once. We covered InfoChimps’ offering of bulk Twitter data in depth this Fall, but the marketplace quietly removed that data after Twitter asked them to “wait” for a second time.
In February we profiled Pete Warden (The Man Who Looked Into Facebook’s Soul), a developer who planned on putting a huge pile of Facebook user data online for academic analysis. As we wrote in that article:
If what people call Web 2.0 was all about creating new technologies that made it easy for everyday people to publish their thoughts, social connections and activities, then the next stage of innovation online may be services like recommendations, self and group awareness, and other features made possible by software developers building on top of the huge mass of data that Web 2.0 made public.
Days later Facebook contacted Warden days later and asked him to hold off on release of that data as well. Last week Warden posted open source code for harvesting the same type of bulk user data from Google Profiles, so the game’s not up yet, not by a long shot.
Why is this kind of big data interesting? This rational may be less applicable in the case of MySpace given its focus on music, or it may be more applicable given the allegedly poorer user demographics on the site compared to Facebook, but here’s how I explained my interest in big social network data analysis in general, as part of a discussion about an excellent special report on big data in the Economist this month.
I think in big data there lies a lot of hidden patterns that represent both opportunities for action and for reflection. At RWW we’re working on trying to find ways to mine data to find news first (we’ve got some interesting methods employed already) and personally, I think the world is an awfully unfair mess and I’m hoping that data analysis will help illuminate some of the hows and the whys. Like the way that real-estate redlining was exposed back in the day by cross referencing census data around racial demographics and housing loan data. That illuminated systematic discrimination against black families in applying for home loans in certain parts of town. So too I think we’ll find a lot of undeniable proof of injustices and clues for how we might deal with them in big data today.
What will we see come out of MySpace’s bulk data? What could we see come from Facebook and Twitter data if only they would let people get their hands on it? Time will tell.