Austin-based data aggregation service Infochimps released several major sets of data extracted from the Twitter API today, as well as Infochimp’s first application and API based on one of these datasets.

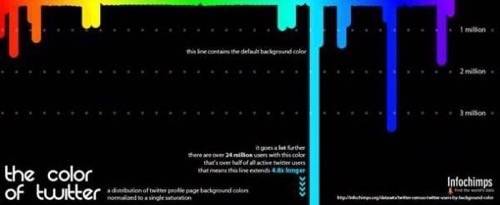
Updating the “Twitter census” data it released in November 2009, the datasets and histograms Infochimps made available today include ones that track Twitter users by follower count and by profile page color (used to make the visualization below).
“Fresh Twitter Data”
While the two sets are among those available for no charge, Infochimps sells the more in-depth and extensive datasets it’s derived from Twitter, proving there’s a continued marketplace for this sort of information. For $300 you can buy the dataset containing an hour-by-hour breakdown of the occurence of hashtags, URLs, and smileys in the 1.6 billion tweets created between March 2006 and March 2010. For $250 you can purchase a dataset extracted from those same 1.6 billion tweets with all mentions of stock tokens and related keywords.
These datasets can provide incredible insights into real-time trends and conversations, as Twitter captures how we relate to one another and what sort of information we share. While information from Twitter has been culled to assess which websites we’ll like and which movies will perform well, analysis from Twitter and from the expanding social graph is really just beginning. Like, for example, the ability to track the time and mention of stock names. The new dataset of stock information offered by Infochimps hopes to demonstrate to the financial industry what the music and film industry already know: big data is a powerful prediction tool.
Trst.me, a Page Rank for Twitter
In addition to releasing information about the counts and keyword content of our tweets, Infochimps offers a new analytical tool: Trst.me, a ranking system for Twitter users. Infochimps has taken 40 million Twitter users and assigned them a score from one to 10 using an algorithm similar to Google’s pagerank calculations. The Trst.me application demonstrates what Sarah Perez wrote here last month: that Twitter influence is not solely based on follower count, but rather by the influence of your followers. In other words, your rank would increase far more by having Justin Bieber follow you than by having me do so. According to Infochimps co-founder Flip Kromer, the company plans on adding additional metrics to this tool so that responses and retweets, as well as influence around a particular topic, can be taken into consideration.

This “trst.me” rank – available as a dataset, an API, and an application – can be used by developers, researchers and businesses to target, rank and understand Twitter users. Access to the API will cost $150 per quarter, but could hold a lot of possibilities for developers wanting to be able to weight Twitter influence or filter those tweets around a particular stream.
Kromer says the decision to build an API was a response from developers he talked to at Chirp, many of whom wanted a quick and agile tool for development, but not necessarily access to the full databases Infochimps can provide.
The Future of Big Data
In 2008, Infochimps released a scrape of Twitter data which was later taken down at the request of the microblogging site over user privacy concerns. But Kromer says Infochimps received Twitter’s blessing at Chirp earlier this month for the release of today’s datasets. In an interview today, Kromer said he was excited about the potential for this and other social media information – most notably public Facebook data. He says he recognizes there are privacy concerns and that people “feel different” about their Facebook and Twitter data, but he argues that open data needn’t be a “nightmare” and hopes to demonstrate the benefits of building “awesome stuff,” including apps and analytics that can “democratize access” to information about users’ interests and behaviors.
As a recent article in The Economist observed, we are at the point of an “industrial revolution of data,” with vast amounts of digital information being created, stored and analyzed. There seems to be ample opportunity in the fields of data aggregation, analysis, and visualization. With a corpus of over 1.6 billion tweets, Infochimps has certainly given us a lot of data to get started on.