
For enterprise teams, data seems to be everywhere, waiting to be unlocked to drive your business goals forward. We sat down recently with two of Nokia’s leading IoT authorities — Marc Jadoul, IoT Market development director, Denny Lee, Head of Analytics Strategy — to talk about how your firm’s data could be oil that drives it forward.
ReadWrite: So this expression – “Data is the new oil” — is something I’ve heard bandied around at conferences and raised a few times. But the thing is, oil could be a fuel, and it could also be a lubricant, in your mind, with your clients, what does that mean?
Marc Jadoul: The way I look at it, is from a value point of view. If you compare the price of a barrel of crude oil with the price of a barrel of jet fuel, there’s quite some difference. Data, like oil, can and must go through a similar refinement process.
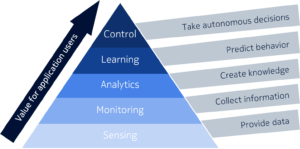
The more it’s refined, the more value it can provide because like fuel, it will support more sophisticated applications. Another way to think about this is like a pyramid – if you’re starting at the bottom of the pyramid, you are basically collecting raw data at the sensor level. At the next stage, you start to monitor this data and begin to discover what is included in it. You’re probably going to uncover some anomalies or trends and based on your analysis, you may uncover critical information that helps you create value for the company driving better decision making so-called Data Driven Decision Making (DDDM).
Then, if you do this decision making in a kind of learning phase based upon cognitive analytics you’re not only going to help make decisions but also predict behavior. Once you can predict behavior then you have gotten to the point of the most refined data, where the data is pure enough to be transformed into knowledge in order to help your machines and applications make autonomous decisions.
What I have described is a value chain where data is providing insight and knowledge to help companies make better decisions and ultimately automating some processes and decision making. I’m making the parallel with the oil industry, not as a metaphor for the lubricant function (laughs), but as compared to the refinement process. The more you refine it, the more it becomes useful and the more value you retrieve.
Denny Lee: When people use the new oil phrase I always think back to the 1970’s – when you control the oil, you control the economy. I think when one says “data is the new oil” it is rooted in this similarity. Data is the new oil also means that if you are able to take hold of that control, you can command that economy and your sector better.
When I hear that term, it also goes back to the idea that “data is the currency.” Data is quite raw in its form and people often use this term quite loosely. Some might think that data, insight, and intelligence are all referring to the same thing. But in fact, we actually make quite a distinction between these. Ultimately, we advocate that data is the raw ingredient and we want to process data that lead to insights. Insights and intelligence are what the business needs. I’m sure we will talk later on how to utilize this intelligence for actionable business purposes.
RW: So when you sit down with a client to discuss how to get them to envision a data-driven innovation within their organization, what’s the first thing that they need to know, the first thing that they should ask?
MJ: I think the first thing they need to do is to understand their own business and what are the challenges and problems that they want to solve. Instead of the contrary, trying to find a problem for their solution. Quoting Simon Sinek, one should start with the “why?” instead with the “how?” or the “what?” question.
DL: Business outcome is definitely one thing but before that you have to ask the question to whom you are speaking to in the organization. Each will have a different organizational boundary or realm of responsibility which will drive a different set of questions.
For example, if you are speaking to a CEO, his or her sand box is huge. On the other hand, you could be talking to a siloed part of the organization where their own universe is very defined. Then you need to understand their business context and their ultimate desired business outcome, You then work backwards and say “ok, what kind of data do you really have?”; and you try to connect the problem to a solution. Obviously when we are talking about the analytics context, it is about processing the data to the point in which it can drive their business outcome.
Then eventually we should talk about crossing organization boundaries. This is a very important point that we should not miss. Sometimes the nuggets of intelligence come only by breaking down the barriers between organizations.
RW: You’ve said in terms of the CEO that you’ve got a bigger sandbox to work in, but when I talk to other folks who are trying to implement a data driven solution of some kind around IoT, the idea of who the champion within an organization is often at the core of who really knows that challenges are within about organization, is there anything you can say about what a typical organizational champion would look like and how to orientate those goals across the organization?
DL: Well, in the IoT context, the organization can often be divided into two realms. The Operations Technology (OT) side and the Information Technology (IT) side. On the OT side your solution could be targeted at the person that controls the infrastructure for his or her company. Depending on the person you are speaking to within that group, they will have different needs.
Let’s take the customer who is focused on predictive maintenance as an example. In this case, he or she may only have budget to focus on maintenance and use big data and machine learning to support the maintenance cycle and to minimize machine outages. This is a very narrow use case with a specific objective. But if you talk to their manager, the scope and the context of the problem they are trying to solve is much broader and might cross organization boundaries
MJ: I really would like to complement this view with a look to a different part of the organization. Besides the leaders that need the analytics to make good decisions, I see the importance of the role of data analyst emerging in a number of organizations. These experts know how to deal with the data – or using the metaphor we used before: control the refinement process. We’re talking here about a different set of skills than the ones traditional IT people have. My educational background is computer sciene and 20 years ago, the basis of computer science education was mathematics. When I looked to the curriculum 5-10 years later, the emphasis had shifted towards algorithms and programming languages. Today, my son is doing his PhD in AI and, believe me, these students must have a very solid understanding of mathematics and statistics again. And let’s not forget that – as data scientists need to support enterprises’ business decisions – they also must have a good level of domain knowledge and business acumen.
RW: So it’s come full circle?
MJ: With most complex problems where you can’t just use raw computer data and number crunching to do something with the data. You really need the domain knowledge to know what’s meaningful and what’s not meaningful. And these are the people that are making it happen in organizations as they are in a support role to the internal decision makers as Denny described.
RW: We see a lot of IoT solutions pitched around the massive amount of data you have or could analyze. So to a point, if you have that data knowledge in house that’s great, but if you don’t, is there a risk of overwhelming a client and offering too many data options, do they really need that talent in house?
MJ: It depends on kind of solutions you want to build, of course. And where you can do filtering and setting thresholds on some of the data, for example if you have a temperature sensor on a refrigeration installation, the only data that you actually want to get hold of are the exceptions or anomalies because if everything is normal there is no need to get overwhelmed by huge volumes of normal data. So what is important is that you do intelligent data collection and try to filter out, and pre-analyze and crunch the numbers as early as possible. To start the refinement process as close as possible to the device where the data is generated.
DL: Let me share with you a view of our thinking. This is applicable to IoT as well. In short, the way we look at data intelligence is similar to a human brain. We are actually driving a notion of intelligence stack. If you think about it in terms of your own brain, there are things that have faster response time and are more autonomous. At this layer, you are processing the environment data but with a narrow scope. Now let’s draw the similarity to IoT. Things are happening on their own and when it needs some feedback adjustments, it is making an autonomous, local decision.
In the next layer, there may be a moderate response time action and it is somewhat autonomous. And then there’s the upper layer that we call augmented intelligence. It serves to help the human; because at the utmost top layer it’s still the human administrator – the human executive making longer term policy changes. And that augmented layer is the top layer of the software where it’s uncovering hidden insights for the human to make better, different and longer term adjustments.
So if you think of these different layers as part of a stack, even if you think about it in an IoT context, say at a factory level: the closer you are to the bottom we’re talking in terms of robotics where things are automatic. And as you go up, it’s more human; and software plays a greater role in terms of discovering insights in order for the human to make better judgements.
MJ: What’s interesting is that this is also reflected at the infrastructure level. Probably you’ve heard of edge cloud or multi-access edge computing or MEC, where you are actually going to do part of the data processing as close as possible to the source. And it is for two reasons: First, you want to reduce the latency in the network, and reduce the turn-around time for decision making. Second, you don’t want to trombone all of these massive amounts of data through the core of your cloud. You only want your users and decision makers to deal with the real useful stuff. When I have to explain edge computing, I sometimes describe it as reverse CDN (content delivery network).
Take a look at what we did years ago when video on demand and live streaming became popular. We were suddenly confronted with the problem that we might not have enough bandwidth to serve each user with an individual stream, and with a possible latency. So, we put caching servers closer to the end-user on which we would put the most popular content and could do some local content navigation and processing, such as fast forwarding and backward, and content adaptation. So this was downstream storage and compute resources optimization. And today we have a number of players on the internet, for example Akamai, who are making good money with such caching and optimization services.
Now, if you look to the Internet of Things, the problem is not in terms of the amount of downstream data like in video but the challenge is in the number of data sources and in the volume of upstream data. Because you have a huge number of IoT devices generating a massive number of data records and what you are actually going to do is put in some kind of upstream caching service that is close to the source to collect the data, do some low level analytics and make sure that you only send information that makes sense further down the cloud for further processing and further refinement, to use the oil industry metaphor once again. And therefore I call edge computing often a kind of “reverse CDN” for it’s supplying the same kind of functions but using a different architecture and operating on flows in a different direction.
RW: OK, so we’ve got someone who wants to invest in a project of whatever kind, typically someone’s got a cost savings or a new revenue stream I guess, but I think more often that not, it seems a go/no-go decision is most often driven by cost reduction or efficiency — which always has appeal in most organizations. Can you both give an example of a data driven process the can unlock not only the cost savings but maybe the decision pathway as well, like an example each?
MJ: I could start with what we are doing with our video analytics solution. This is an example of an application that uses massive volumes of data streamed by e.g. closed circuit video surveillance cameras.
In cities you have hundreds or thousands of these cameras that are creating huge numbers of live video streams. Generally, there is not enough staff to look at all the screens simultaneously, because it would be extremely expensive and inefficient to have people watch all these video streams 24/7. So, what Nokia’s solution does is analyze these videos and look for anomalies. There are plenty use case examples, like a car driving in the wrong direction, turmoil in an airport, some people or objects making unusual movements. What we’re actually doing is collecting these video data and putting it through the refinement chain, processed through a number of algorithms that recognize specific situations and detect anomalies. Adding AI capabilities to it, the system becomes self-learning and can identify, alert and predict any sort of “happening” that is out of the ordinary. This is helping decision making but at the same time it’s also an enormous cost saving because cities and security firms need only a fraction of the people. Analytics technologies are actually making these kinds of video surveillance solutions possible and affordable.
RW: Right, human eyes are not very scalable.
MJ: Right, human eyes are not very scalable and probably 99.99% of this CCTV video content doesn’t need attention. So you need to learn to filter the data as close as possible the source and only continue working with what is relevant.
DL: So Trevor, I’ll also give you a few sets of examples. The first group would be ones for accelerating resolution faster: such as predictive maintenance, “Next Best Action,” under the realm of predictive care for recommending workflow actions to care agent, and automated root cause analysis. These example use cases were previously done manually. You wait for some faults to occur and then you look into it. With automation and prediction; instead, some machine learning solution can predict potential fault occurrence ahead of time and you can minimize expensive maintenance action for fixing the problem after the fact.
Another set of examples is under the category of customer centricity with the use of artificial intelligence. Many customers are interested in this topic because at the end of the day they recognize that their competition is also trying to appease their end customers as best as they can. And whoever can do that best wins the day. So appreciating and understanding the customer experience and being able to predict that and respond to their needswould be an important aspect of big data analytics solution. For example in the context of networking solution providers and operators, knowing ahead of time that a congestion is going to happen and reacting to it, would be important. Maybe having a well-managed, butdegraded, performance is better than not having any services at all in certain circumstances. So getting ahead of the problem with customer centricity is also a form of AI application – understand their experience and then acting accordingly. The third one, I would say is the augmented reality use cases which appeals to the higher level executive and the policy owners of the operators of the IoT enterprise.
Another class of problems would fit under the category of “optimization.” If you look at a set of business outcomes, you can set up the problem as an optimization problem: these are my sandboxes, here is my raw data and my KPIs and that is what I want to optimize as goals. The system can then be set up to optimize it. This is related to the point where one has the opportunity to break down organizational silos and optimize certain outcomes that are previously undiscoverable when the organizations are siloed. Such type of intelligence appeals more to the executive and policy owners of the organizations.
This article as produced in partnership with Nokia. It is part of a series of articles where the team from Nokia will be providing expert advice and delve further into data analytics, security and IoT platforms.

















