GlusterFS was introduced back in 2007, as an open source network-attached storage system that used Ethernet or InfiniBand RDMA to pool together multiple storage volumes into one colossal pool. It became a cloud storage system in 2009, meaning that it added the elasticity and self-service provisioning necessary to qualify for the official “cloud” moniker. And although it was designed for enterprises, that didn’t stop some very clever coders from reworking it into a locally-mountable cloud storage store, now called HekaFS.

Last October, Red Hat acquired Gluster, the file system’s parent, for $126 million in cash. Today, the New England-sounding name is no more, but the vision lives on under the unsurprising name Red Hat Software Appliance.

It is essentially what a CIO first thinks of when presented with the idea of cloud service for the enterprise: an unlimited storage pool made up of petabytes of volumes brought together by the network. Red Hat’s package, delivered for the first time last Thursday, pairs Enterprise Linux together with what has been called GlusterFS, for a massive storage pool that may be logically partitioned, with those partitions applied to users or groups.
“By scaling performance and capacity linearly, capacity is able to be added as required in only a few minutes across a wide variety of workloads without affecting performance,” reads a Red Hat white paper published late last week. “Storage can also be centrally managed across a wide variety of workloads enabling operations to more efficiently manage storage used for a variety of purposes.”
This week, Red Hat is also making its commercial implementation of GlusterFS available as a virtual storage appliance, for businesses who are leasing their storage from Amazon.
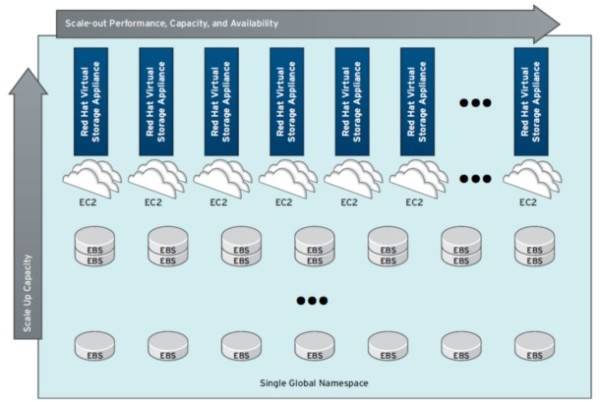
The virtual version of the appliance aggregates Amazon’s Elastic Block Storage (EBS) into pools of up to 100 TB, multiple instances of which may be centrally managed through a centralized service. One of the main distinguishing factors between the Gluster approach and IBM’s is that the former does not rely on metadata servers for clustering physical storage engines together. Instead, Gluster’s Unified File and Object Storage (which may continue to bear that name) utilizes its own data hashing algorithm to locate files, containers, and objects within a pool. This way, says Red Hat, performance factors scale down only linearly instead of exponentially as storage capacity scales up linearly.

















