It’s hard to keep track of all the database related terms you hear these days. What constitutes “big data”? What is NoSQL, and why are your developers so interested in it? And now “NewSQL”? Where do in-memory databases fit into all of this? In this series, we’ll untangle the mess of terms and tell you what you need to know.

The first part covers data, big data, databases, relational databases and other foundational issues. In part two we’ll talk about data warehouses, ACID compliance and more. In part three, we’ll cover non-relational databases, NoSQL and related concepts.
Data
The best definition of data I’ve been able to find so far is from Diffen:
Data are plain facts. When data are processed, organized, structured or presented in a given context so as to make them useful, they are called Information.” On the subject of whether data is singular or plural:
It should be noted that data is plural (for datum), so the correct grammatical usage is “Data are misleading.”. However, in practice people tend to use data as a singular form. e.g. “This data is misleading.”
Big Data
In short, big data simply means data sets that are large enough to be difficult to work with. Exactly how big is big is a matter of debate. Data sets that are multiple petabytes in size are generally considered big data (a petabye is 1,024 terabytes). But the debate over the term doesn’t stop there.
There are other factors that can make data difficult to work with, such as the speed at which data is updated or the data’s lack of structure. Clive Longbottom of Quocirca suggests the term “unbounded data” for data that is fast or unstructured:
Indeed, in some cases, this is far more of a “little data” issue than a “big data” one. For example, some information may be so esoteric that there are only a hundred or so references that can be trawled. Once these instances have been found, analysing them and reporting on them does not require much In the way of computer power; creating the right terms of reference to find them may well be the biggest issue.
Where might you run into big data or unbounded data? Social networks, where of users are adding status updates and comments at a high-speed. Or sensor networks with data about the surrounding environment is being stored at a fast pace. Or genomics, where huge amounts of genetic data is being processed.
Database
A database is simply a way of storing and organizing data. According to Wikipedia Simple English: “The data can be stored in many ways. Before computers, card files, printed books and other methods were used. Now most data is kept on computer files.” A non-electronic database could be a card catalog or a filing cabinet.
When the term “database” is used, it’s usually to refer to a database management system (DBMS), which is a piece of software designed to create and manage electronic databases. A simple example might be an electronic address book.
Data Store
Data store is an even more general term than database. It’s a place where any type of data is kept. Databases are data stores, but a text file full of data could also be a data store. A text file with a list of names and addresses is a data store, but an address book application on your computer is a DBMS.
Schema
According to Wikipedia, a database system’s schema is “its structure described in a formal language supported by the database management system (DBMS) and refers to the organization of data to create a blueprint of how a database will be constructed (divided into database tables).”
Relational Database or RDBMS
Here’s where things get interesting. A relational database is a specific type of database in which data is stored in “relations.” Relations are usually tables, with rows representing different “things” and columns representing different attributes of those things.
For example, let’s look at a hypothetical database for an oversimplified blogging system. Each post has a set of attributes, such as title, author, category and the post content itself. Every post has these attributes, even if some are left blank. Here’s a example:
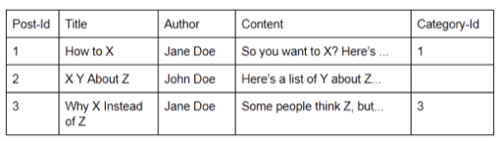
The blogging system database might also have a table called “categories” that looks something like this:
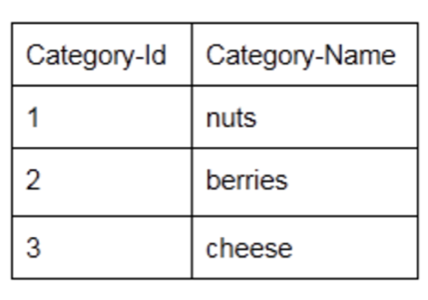
The database’s schema includes the facts that post content is stored in the posts table, that posts use the Category-Id attribute for categorization, that the names of categories are stored in the categories table, etc.
When we want to view – or “query” – a post, the software fetches each attribute from each column for the row of the post you want to look at and assembles it into a post.
If you want to query a list of categories that have been created but not used in posts, the software would cross-reference the categories table with the posts table, combine them into a new table and return a list of categories without posts. This cross-referencing and combining process is called “joining.”
Here’s a more traditional example:
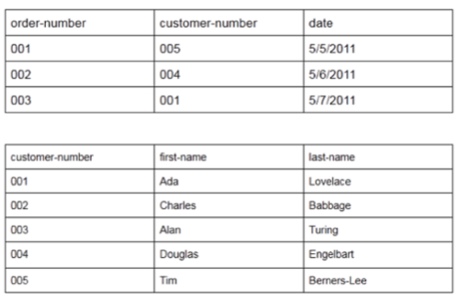
Imagine this system extended out over a number of years. You could use queries to determine which of your customers hadn’t placed an order in the past year and either call them or close their account.
This may seem straight forward, but the underlying mathematics is complex. It’s based on the relational model, which was created by E.F. Codd in 1969.
RDBMS stands for relational database management system, which is the type of software used to create and manage relational databases. Examples include: Oracle RDBMS, IBM DB2, Microsoft SQL, Microsoft Access, MySQL, PostgreSQL and FileMaker.
SQL
SQL stands for Structured Query Language. It specifies the commands the blog software must give the database server in order to display a particular blog post or list of tags. It makes it easy for someone with experience in one RDBMS to use another RDBMS with minimal re-training.
Here’s the query, written in SQL, that would join the categories table with the posts table and check for unused categories in the blog database example from above:
SELECT categories.Category-name, posts.Post-Id FROM categories JOIN LEFT posts ON categories.Category-Id = posts.Category-Id WHERE Post-Id IS null
Special thanks to Tyler Gillies for his help with this series

















