It’s hard to keep track of all the database-related terms you hear these days. What constitutes “big data”? What is NoSQL, and why are your developers so interested in it? And now “NewSQL”? Where do in-memory databases fit into all of this? In this series, we’ll untangle the mess of terms and tell you what you need to know.

In Part One we covered data, big data, databases, relational databases and other foundational issues. In Part Two we talked about data warehouses, ACID compliance, distributed databases and more. Now we’ll cover non-relational databases, NoSQL and related concepts.
Non-Relational Database
A non-relational databse is simply any type of database that doesn’t follow the relational model. See Part One for a full definition of relational database.. Several types of database get lumped into this category: document-oriented databases, key-value stores, BigTable-clones and graph databases are the main ones, but there are a few others.
We did an overview of the field a couple years ago, and have covered many databases that fit under this large umbrella.
Non-relational databases tend to be used for big data or unbounded data. Although caching and in-memory data can mitigate many of the problems a relational database may encounter, there are times when data is either being updated too quickly or the data sets are simply too large to be handled practically by a relational database.
Non-relational databases are usually thought of as not being ACID compliant, but some some are.
NoSQL
NoSQL is shorthand for non-relational database. Some have suggested that “no” should in this case stand for “not only.” According to the Wikipedia, the first known use was by Carlo Strozzi, but he was using it to refer to a relational database that didn’t expose a SQL interface. He later said that the way the term is used now is more accurately “NoREL,” not “NoSQL.” Perhaps the earliest use of the term with its current meaning was the first NOSQL Meetup.
CAP Theorem
According to Wikipedia, the CAP theorem states that a distributed computer system can’t guarantee all of the following:
- Consistency, all nodes see the same data at the same time
- Availability, a guarantee that every request receives a response about whether it was successful or failed
- Partition tolerance, the system continues to operate despite arbitrary message loss
The CAP theorem was proposed by computer scientist Eric Brewer of University of California, Berkeley and later proved by Seth Gilbert and Nancy Lynch of MIT.
BASE and Eventual Consistency
Most of the non-relational databases that have become popular in recent years are capable of being constructed as distributed databases as well, and that’s often the reason that they are used. The CAP theorem tells us, however, that we can’t always have both ACID levels of consistency and high availability. Many non-relational databases therefore use a different standard for consistency: BASE, which stands for Basically Available Soft-state Eventually.
In a distributed database system, different copies of the same data set may exist on several servers. We of course want these data sets to stay consistent. But one of the main points of having multiple servers is to improve performance. We don’t necessarily want to tie up up each server every time a database table is updated. So we settle for “eventual consistency.” “Eventual” usually actually means less than a second. The concept is discussed in my greater depth here.
MapReduce and Apache Hadoop
Map and reduce are methods in computer science for manipulating data. MapReduce is a distributed computing system created by Google specifically for working with large data sets and distributed data stores. It’s named after these two computer science methods.
Apache Hadoop is an open source implementation of the ideas from a paper Google published on MapReduce. MapReduce is used in conjunction with a data store called BigTable, which we’ll explain below. Hadoop has its own data store called HBase, which is based on ideas explained in a paper on BigTable.
The collection of computers that comprise a distributed computing system is called a “cluster.” Each computer in the cluster is referred to as a “node.” Here’s how Wikipedia explains MapReduce:
- “Map” step: The master node takes the input, partitions it up into smaller sub-problems, and distributes those to worker nodes. A worker node may do this again in turn, leading to a multi-level tree structure. The worker node processes that smaller problem, and passes the answer back to its master node.
- “Reduce” step: The master node then takes the answers to all the sub-problems and combines them in some way to get the output – the answer to the problem it was originally trying to solve.
Map and reduce is a common system used for querying data in non-relational databases, but the approach may be very different from MapReduce. For example, this Apache CouchDB tutorial explains how to use JavaScript to write a map and reduce function that finds products and prices in a database. The map function in this example finds and returns a list of products and the reduce function checks to make sure there is a price for each result and returns the price.
Sometimes the term “MapReduce” may refer to this programming method, other times it may refer to Google/Hadoop distributed computing approach (which is a specific application of these methods).
Key-Value Store
Key-value stores are schema-less data stores. As Oren Eini writes, “The simplest No SQL databases are the Key/Value stores. They are simplest only in terms of their API, because the actual implementation may be quite complex.”
Using the blog example again (see the relational database section of Part One and the columnar database section of Part Two), a blog that uses a key-value store might store posts with just a key (say, a unique number for each post) and then everything else will be lumped together as the value. Here’s our blog example in a very simple key-value store:
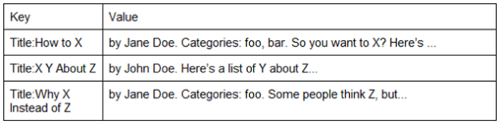
The lack of a schema can make it much more difficult to create custom views of the data, which is one of the reasons map and reduce are used to query many non-relational databases.
Membase and Redis are examples of key-value stores.
Document Database
Document databases contain information stored in the form of documents. They are considered semi-structured. A document-oriented database is more complex than a key-value store, but simpler than a relational database.
Here’s the old blog database example again:
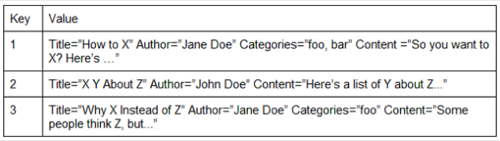
Notice that in this version, there’s no need for the “Categories” field to be set in the second document. Contrast this with the relational database, which had the field but left it blank.
This allows for more flexibility than a relational database, while providing more structure than a key-data store and making it easier to retrieve and work with the stored data. It would be much easier to create a list of posts with a common tag using a a document database than a plain key-value store.
Lotus Notes is an early example of a document-oriented database. Apache CouchDB and MongoDB are two more recent examples.
BigTable-clone, Tabular Stores or Column Family Database
BigTable is a column-oriented, distributed, non-relational data store created by Google. Like MapReduce, Google published an academic paper detailing its workings. That lead to a few clones, most notably HBase, the data store used with Apache Hadoop. Apache Cassandra is also influenced by BigTable. Some refer to them as “tabular stores.” Eini calls these “column family databases.”
BigTable-clones are actually very similar to relational databases, but do away with a few structural elements. This necessitates using complex search methods, but makes it possible to scale to petabytes of size. BigTable and its clones store data in columns, super-columns and column-families. We can think of super-columns and column-families as “columns of columns.”
If you want more information about how BigTable actually works, you can read Google’s paper or the short article Understanding HBase and BigTable by Jim R. Wilson.
Object Database
Object databases apply the principles of object-oriented programming to database design. What this means is programmers can store data in databases using the same structure that the computer programs that will eventually access the program use. This means the program doesn’t need to process the data into another structure when accessing the database. Instead of using a query language, such as SQL, a program can perform operations on the data immediately. One downside is that object databases are often tied to a specific programming language, such as Java or C++.
One of the most popular object databases is Objectivity/DB, which is used in applications ranging from computer aided drafting to telecommunications to scientific research.
More information on object databases can be found here.
Graph Database
Graph databases apply graph theory to the storage of information about the relationships between entries. The relationships between people in social networks is the most obvious example. The relationships between items and attributes in recommendation engines is another.
Yes, it has been noted by many that it’s ironic that relational databases aren’t good for storing relationship data. Adam Wiggins from Heroku has a lucid explanation of why that is. Short version: among other things, relationship queries in RDBSes can be complex, slow and unpredictable. Since graph databases are designed for this sort of thing, the queries are more reliable.
Popular examples include Neo4j and DEX.
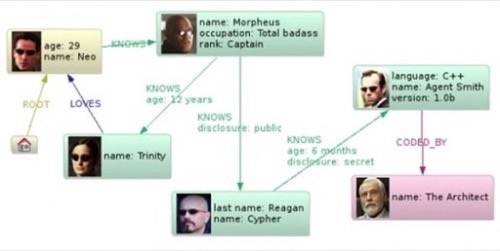
We’re partial to this illustration from a presentation by Peter Neubauer, the COO of Neo4j sponsor company Neo Technologies, Neo4j works:
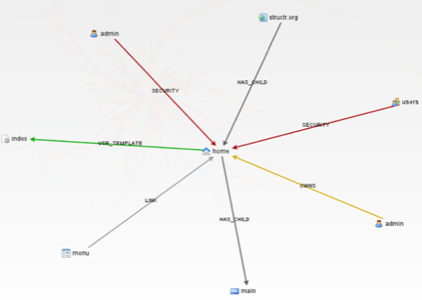
Another good example comes from structur, a content management management system that uses Neo4j. This illustration shows how the graph database model can be applied to content (to a blog system, for example):
NewSQL
NewSQL is a term coined by 451 Group analyst Matthew Aslett to describe a a new wave of software projects that try to make RDBMSes more scalable.
Examples include:
- Drizzle, which tries to rebuild the popular RDBMS MySQL from the ground up.
- HandlerSocket, a MySQL plugin that provides key-value store functionality.
- VoltDB, an in-memory, distributed relational database that is fully ACID compliant.
Special thanks to Tyler Gillies for his help with this series

















