This is a guest post by Nitin Karandikar, author of the Software Abstractions blog.

Recently I was looking at the log files for my blog, as I regularly do, and I was
suddenly struck by the variety of search queries in Google from which users were
being referred to my posts. I write often about the different varieties of
search – including vertical search, parametric search, semantic search, and so
on – so users with queries about search often land on my blog. But do they always find
what they’re looking for?
All the major search engines currently rely on the proximity of keywords and
search terms to match results. But that approach can be misleading, causing the
search engine to systematically produce incorrect results under certain
conditions.
To demonstrate, let us take a look at three general use cases.
[Note: The examples given below are all drawn from Google. To be fair, all themajor search engines use similar algorithms, and all suffer from similar
problems. For its part, Google handles billions of queries every day, usually
very competently. As the reigning market leader, though, Google is the obvious
target – it goes with the territory!]
1. Difficulty in Finding Long Tail Results
Take Britney Spears. Given the current popularity of articles, news, pictures, and
videos of the superstar singer, the results for practically any query with the
word “spears” in it will be loaded with matches about her – especially if the
search involves television or entertainment in any way.
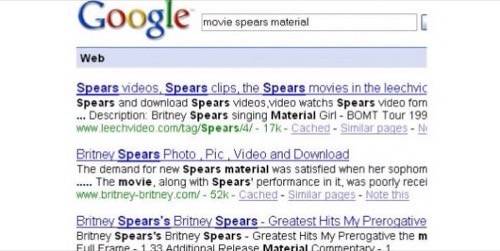
Let’s say you’re watching the movie
Zulu and you
start wondering what material the large spears that all the extras are waving about are made of. So, you go to Google and type in “movie
spears material” – this is an obviously insufficient description, as
the screen shot below shows.
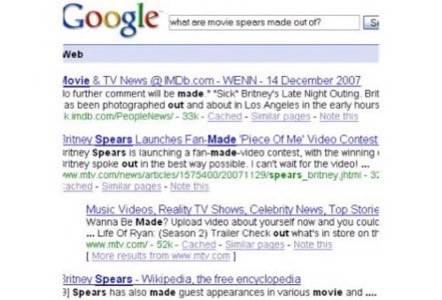
What happens if you expand on the query further – say:
“what are movie spears made out of?” – does it
help?
The general issue here is that articles about very popular subjects accumulate
high levels of PageRank and then totally overwhelm long tail results. This makes
it very difficult for a user to find information about unusual topics that
happen to lie near these subjects (at least based on keywords).
2. Keyword Ordering
Since the major search engines focus only on the proximity of keywords without
context, a user search that’s similar to a popular concept gets swamped with
those results, even if the order of keywords in the query has been
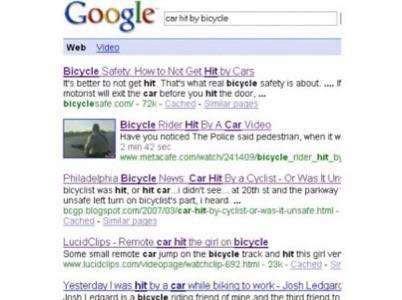
reversed. For example, a tragic occurrence that’s common in modern life is
that of a bicycle getting hit by a car. Much less common is the possibility of a
car getting hit by a bicycle, although it does happen. How would you search for
the latter? Try typing “car hit by bicycle”
into Google; here’s a screen shot of what you get. [Note the third result,
which is actually relevant to this search!]
3. Keyword Relationships
Since the major search engines focus only on the keywords in the search phrase,
all sense of the relationship between the search terms is lost. For example,
users commonly change the meaning of search terms by using negations and
prepositions; it is also fairly common to look for the less common members of a
set.
This takes us into the realm of natural language processing (NLP). Without NLP,
the nuances of these query modifications are totally invisible to the search
algorithms.
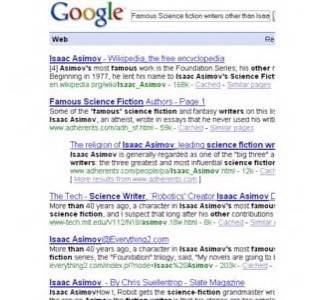
For example, a query such as “Famous science fiction
writers other than Isaac Asimov” is doomed to failure. A screen shot
of this search in Google is presented below. Most of the returned results are
about Isaac Asimov, even when the user is explicitly trying to exclude
him from the list of authors found.
All of the searches shown above look like gimmicks – queries designed
intentionally to mislead Google’s search algorithms. And in a sense, they are;
these specific queries can be easily fixed by tweaking the search engine.
Nevertheless, they do point to a real need: the value of understanding
the meaning behind both the query and the content indexed.
Semantic Search
That’s where the concept of semantic search comes in. I attended a media event
earlier this year at stealth search startup
Powerset
(see:
Powerset
is Not a Google-killer!), at which they showcased a live demo of their search
engine, currently in closed alpha, that highlighted solutions to exactly this
type of issue.
For example, type “What was said about Jesus” into a major search engine, and
you usually get a whole list of results that consist of the teachings of Jesus;
this means that the search engine entirely missed the concepts of passive voice
and “about.” The Powerset results, on the other hand, were consistently on
target (for the demo, anyway!).
In other words, when you look at just the keywords in the query, you don’t
really understand what the user is looking for; by looking at them within
context, by taking into account the qualifiers, the prepositions, the negatives,
and other such nuances, you can create a
semantic
graph of the query. The same case can be made for semantic parsing of the
content indexed. Put the two together, as Powerset does, and you can get a much
better feel for relevance of results.
What about Google? I’m sure the smart folks in Google’s
search-quality
team are busily working on this problem as well. I look forward to the time
when the major search engines handle long tail queries more accurately and make
search a better experience for all of us.
Update: for an expanded version of this article with real-life user queries, see my blog.

















