The founders of the data extraction and API creation service Dapper announced this week that their aim is to leverage Dapper in the service of ad networks and derive a semantic index of pages around the web from that activity. They will launch their ad powering product at Ad:Tech in April. Essentially, it will perform ad funded indexing of the semantic web.

Here’s how it will work: Dapper lets users identify and tag particular fields on any page. It then extracts the value in that field and makes it available in XML. As a result of this advertising activity, Dapper believes a substantial quantity of pages around the web could have fields of interest delineated and tagged with relevant terms. Relationships between pages and fields and terms and tags can all be extracted and analyzed from this aggregated activity.
The company has already built a demonstration semantic search engine based on Dapper activity and its ability to parse search results by semantic meaning and detail is quite sophisticated. The potential applications of a semantic index built by Dapper are really exciting to consider.
Dapper currently has 35,000 extraction functions (Dapps) created, but they are betting that a clear profit motive will incentivize advertisers to create many, many more. Advertisers will pay to have web content delineated by field and categorized.
The company argues that advertisers see substantially increased relevance and click-through if ads can be served based on very specific fields of content on a page. Early prototypes run on top music site Pitchfork and book summary site Shvoong saw 100 to 500% increases in CTR.
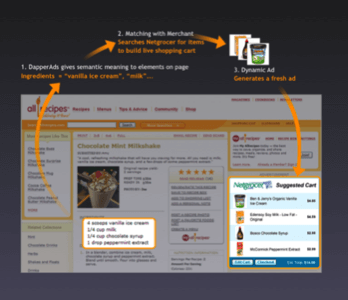
While Dapper’s approach would likely leave the vast majority of fields on a page unindexed, it could also rack up a whole lot of semantic knowledge by riding the profit motive to discover the semantic meaning of the most monetizable fields on a far greater number of pages than would likely be analyzed otherwise. What better way to analyze the web than to ride along with ad networks? I can’t think of any better way.
I think Dapper has a shot at helping fund the semantic analysis of much of the web. What will they do with the data other than use it to contextualize ads? That’s another question, but an interesting one to consider.
Dappercamp was a great event this week and the tool itself is one I highly recommend. It’s in startup mode and I’ll be frank – many of the output formats simply don’t work and there are a number of errors throughout the site. None the less, I derive significant value for my work every time I engage with it. Here’s a screencast tutorial I recorded on the service. Several Dapps, Dapper-created data extractions, have become daily go-to sources of information for me – but I also recognize that only so many people are going to be as excited about this technology for research purposes. For the rest of the world, for the viability of the company, and for the potentially gigantic secondary benefit of widespread semantic indexing – I think putting Dapper in service of ad networks is a plan of simple brilliance.

















