This blog was founded in 2003 on the philosophy of a read/write Web – a Web in which people can create content as easily as they consume it. This trend eventually came to be known as Web 2.0 – although others preferred Social Web – and was popularized by activities like blogging and social networking.

It would be easy to say that the ‘social’ element is still the primary part of today’s Web, since the popular products of this era enable you to say what’s on your mind (Facebook), what’s happening (Twitter), or where you are (Foursquare). All of these are mostly social activities. But more significantly, these and other products output data that will increasingly be used to build personalized services for you.
The more data there is, the better Web services will be at delivering personal value to you. While part of this increase in data is coming from social data from the likes of Facebook and Twitter, much of it is coming from the Internet of Things and data uploaded by governments and organizations. In short: the read/write Web is now much more than the Social Web.
So how did we arrive at a Web that is less about social and more about you?
It’s not how much content you consume that is important, it’s about what you do with data.
After the peak of Web 2.0, we (meaning all of us) began to get overwhelmed with the choice of content available. We thought we had to actually ‘read’ as much of that content as possible. So we watched YouTube, chatted on MySpace and Facebook, read blogs, followed lots of people on this new thing called Twitter, and so on. By the end of 2008, we were exhausted by all of this CONTENT. How could we possibly keep up?!
In 2010, we’re still struggling to digest all of what social media throws at us. However, a shift has been happening since 2009 which alleviates the problem. We’ve begun to realize that it’s not how much content we consume that is important: it’s what we do with all of the social and other data available to us. The social is still important, but the resulting data is – slowly – becoming more important because it can be analyzed, filtered, mashed up and personalized.
Structured Data & Internet of Things
Two relatively new trends are driving this change.
If I was an entrepreneur or developer, I wouldn’t be thinking about social anymore. I’d be thinking: How can I use all of this data and build on top of it?
The first is the increasing amount of data being uploaded to the Web by governments, organizations and people. Much of this data is being structured using Semantic Web technologies like RDFa or microformats. In other words, it is categorized and encoded with meaning that machines can process. Recent examples include U.S. and U.K. government data, Best Buy’s store and product data and Facebook’s Open Graph.
And then we have the Internet of Things: an evolving trend where real-world objects and ‘things’ are connected to the Internet via technologies such as sensors and RFID tags – everything from cars to houses to roads and more. The upshot is that the Web is about to experience a data explosion, as billions of sensors and other data input and output devices upload exabytes of new data to the Web.
How do We Use This Data?
If we add together social data from the likes of Facebook and Twitter, data from governments and businesses, and data from sensors and RFID, this is a huge amount of data. Most of it isn’t for “consuming.” Rather, the value of all of this new Web data will be in how it’s filtered, mixed together (“mashed up”) and personalized in new Web services – most of which haven’t yet been built.
Adam Greenfield is one of the leading thinkers of the Internet of Things; I interviewed him earlier this year about his book called Everyware. Greenfield recently wrote a post describing a near future scenario for non-technical people using the Web. He posited a use case where his mother would be able to plan a train trip to see her son, by creating an “ad-hoc service” that tapped into the Web and utilized real-time data sources.
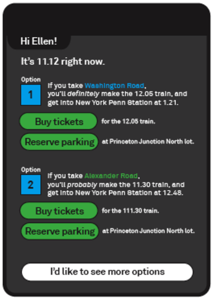
In 2010, his mother would have to find and “read” several different applications in order to plot her travel schedule, and some of that information isn’t even currently on the Web. Greenfield envisions a near future where his mother can essentially “write” her requirements into her mobile or other device, and the Web will deliver a personalized schedule to “read.” You can view a diagram of Adam’s concept here (PDF).
Successful products in the Web 2.0 era had a strong social element: YouTube, MySpace and Flickr were a few relatively early examples. In the current era of the Web, which began to form in early 2009, the focus has shifted from social to data-driven software. Successful products of this era of the Web will be ones that filter, structure and personalize this vast amount of data coming onto the Web.
So if I was an entrepreneur or developer wondering what to build for this era of the Web, I wouldn’t be thinking social. I’d be thinking: How can I use all of this data and build on top of it? There are incredible opportunities out there for you.
This current era of the Web doesn’t have a name, which is probably a good sign! One thing is for sure though: It’s still a read/write Web – only now you’re reading and writing data from much more than just social services. You’re increasingly interacting with “things,” organizations, governments – virtually anything that can connect to the Web.