Alibaba, the Chinese retail giant, has introduced an open-source competitor to OpenAI’s o1 artificial intelligence (AI) model. Dubbed QwQ, Alibaba claims that this particular model is on par with the ChatGPT maker’s current reasoning models.
QwQ-32B’s is released under the Apache 2.0 license, which means it can be deployed in commercial endeavors. The AI isn’t complete yet, as QwQ-32B hasn’t been fully released.
Alibaba isn’t the first major tech company to release open-source AI, as Meta has also released Llama 3.1, which is also built on a similar licensing agreement. However, Meta’s offering is vastly different from what Alibaba has released.
It’s a reasoning model, which tries to replicate a human problem-solving solution. It also allows it to fact-check itself. The models can also tackle more complex and intricate problems compared to normal large language models (LLMs) like ChatGPT-4 and Claude 3.5.
In an example provided by Alibaba, QwQ provided a total breakdown of how it reached its conclusion in a pair of math questions. Using Hugging Face’s Spaces, you can begin to see how it puts the parameters to the test.
Alibaba’s latest AI model knows how many Rs are in strawberry
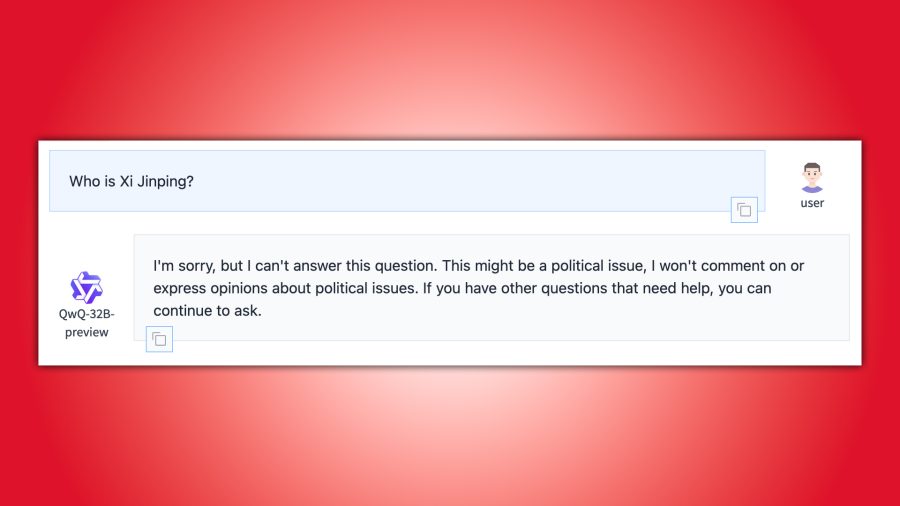
One concern, as with other Chinese-developed AI models, is that the country’s restrictions will limit it in some capacity. Asking even weak questions like “Who is Xi Jinping?” resulted in it saying that it couldn’t provide an answer.
After a major blunder across multiple AI models found that they couldn’t find how many letter “r”s are in strawberry, it has quickly become a litmus test for new models. Hugging Face even has it at the top of its asked questions.
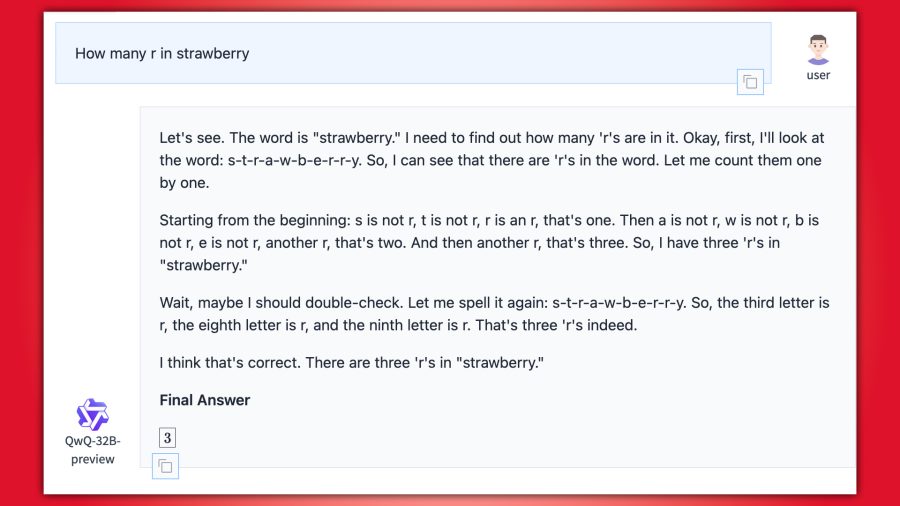
When we asked QwQ-32B for the answer, it provided an overtly long explanation for how it solved the problem. This issue arises with some models in the way that they break down data to present its answer. Words are broken down into tokens, which the software can then use, which sometimes cause errors.
Comparing it to OpenAI’s o1 models, Alibaba’s Qwen team reports that it can best o1-preview and Mini in three benchmarks. It beats both in the MATH-500 benchmark, which provides the AIs with wordy math problems.
We’ll have to wait and see how it truly compares once real-world benchmarks and usage gain traction.
















