











Despite a meager track record for generating outsized returns, investors keep piling money into open source start-ups. As reported by The Wall Street Journal, a minimum of 110 “open source startups” had raised more than $7 billion from venture capitalists as of 2015, up over 100% since 2013.
The hottest open source companies are focused on big data, with companies like DataStax, Cloudera, and MongoDB bagging billion-dollar valuations as they earn ever-increasing revenues. But even hotter, according to new data from mutual fund filings and Dow Jones VentureSource, are proprietary big data software startups.
This is surprising in some ways, as most big data technology is open source. The trick seems to be how companies choose to monetize it.
Valuing open source
The only public benchmark for open source big data companies is Hortonworks, which went public at a billion-dollar valuation only to see its value slide to $638 million as of the time of this writing.
Much of the investor concern over Hortonworks‘ valuation remains a persistent concern that the company’s pure-play open source business model doesn’t work. This is ironic given that Hortonworks has taken far less time to get to $100 million in revenue than some industry bellwethers – like open source peer Red Hat, not to mention Oracle and Salesforce.
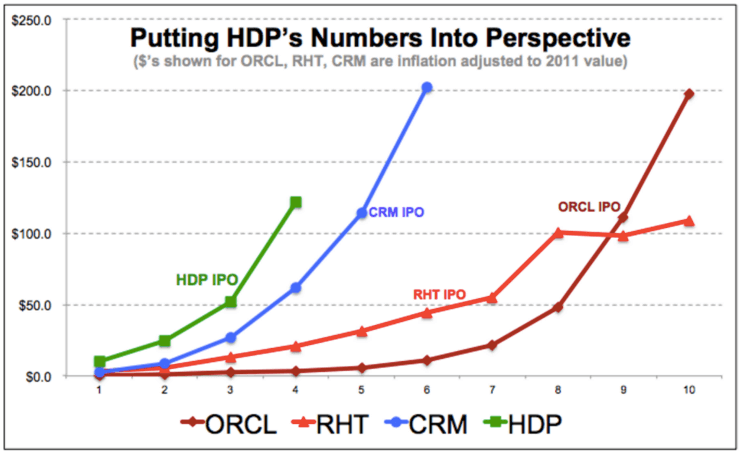
Even so, this concern over open source business models plagues other companies, too, including MongoDB, which has seen its mutual fund investors write down their valuations of the company by 30% in the last two years:
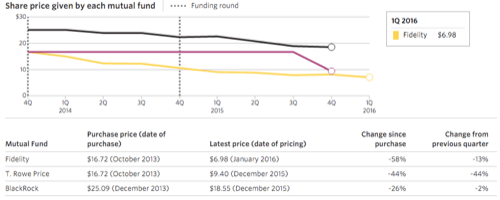
Proprietary software’s free pass
The more a big data company focuses on proprietary differentiation, even for otherwise open source products, however, the more investors have tended to give it a free pass.
Take Cloudera, for example, perhaps the closest analog to Hortonworks. Both companies offer Hadoop distributions, but Cloudera has been much more willing to offer proprietary add-ons to complement its open source platform. In response, investors have bid up its still-private shares by 75% in the last two years:
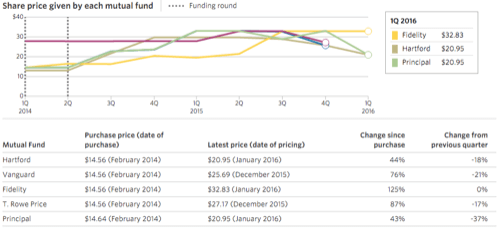
Step away from open source entirely, however, and valuations have risen even more.
Domo – a big data analytics startup that has been happy to question Hadoop’s right to the big data throne – has seen its valuation go up 90% in the last two years, despite going against the open source grain:
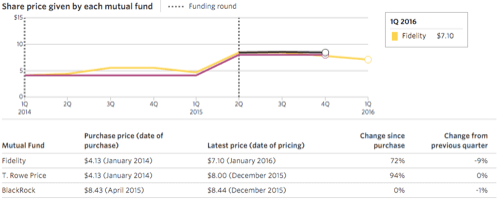
Or take Palantir, whose software is used to uncover patterns in massive quantities of data. Palantir uses and contributes quite a lot of open source software, but makes its money selling proprietary software. Its reward? A 152% increase in valuation since Q3 2012:
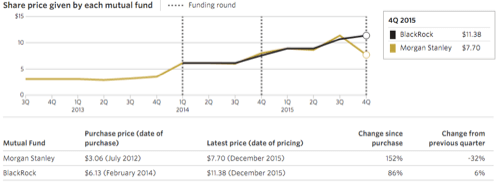
Selling more than free
None of which is to suggest that proprietary software is better than open source. With over 15 years working for open source companies, I simply don’t believe that.
But it is an indication that the right way to monetize open source is by selling something other than open source software. Former Wall Street analyst Peter Goldmacher nailed this years ago, arguing that the companies getting rich in the “big data Gold Rush” are the “apps and analytics vendors that abstract the complexity of working with very complicated underlying technologies into a user-friendly front end,” or those “business people that have identified opportunities to use data to create new opportunities or disrupt legacy business models.”
The first group fits the Palantir model. The second includes companies like Facebook or Uber.
Investors aren’t infallible in their estimation of where value lies in the big data ecosystem, as Hortonworks’ Shaun Connolly, vice president of strategy, points out in the article referenced above. But they’re a reasonable indication of where most of the big data money is pooling. And while open source is an essential ingredient of nearly all big data companies, delivering proprietary value on top of that software seems best at paying the bills.




















